昨今はチャージリサイクリングによる低消費電力化の研究が活発です。その1つを今日はお話します。
チャージリサイクリングでViを下げる
以前の記事で解説した数式を1つ思い出していただきたいのですが、CMOSLSIの消費電力の算出で、Pcは(1)「C・Vi・Ve・f」もしくは(2)「C・Ve2・f」で表されます、と申し上げました。このうちViを、「チャージリサイクリング」と呼ばれる低消費電力化を図る技術についてご紹介します。
チャージリサイクリング技術とは?
ブログをご覧の皆様には基本的レベルの事ですが、重要なのであえて申し上げますと、LSIの内部ノードは、演算動作に応じてVeと0の間を遷移します。内部ノードを、0→Veにする時は電源から所定のノードへ電荷を供給し、Ve→0にする時はノードの電荷をGNDへ引き抜いています。
演算動作中、演算を実施しているノードと、これから演算を開始するノードがLSI内で同時に存在します。すなわち“Ve”へ充電したいノードと“0”へ放電したいノードが混在する。ということが頻発します。この状態でノード毎に充放電すれば、当たり前ですが消費電力量は増えますね。
チャージリサイクリングとは、あるノードをVe→0にする時、その電荷をすべてGNDへ捨てるのはもったいないので、電荷の一部を0→Veにしたい別ノードへ渡して再利用する技術なのです。
なんとも賢い方法ですね。原理図を示します。
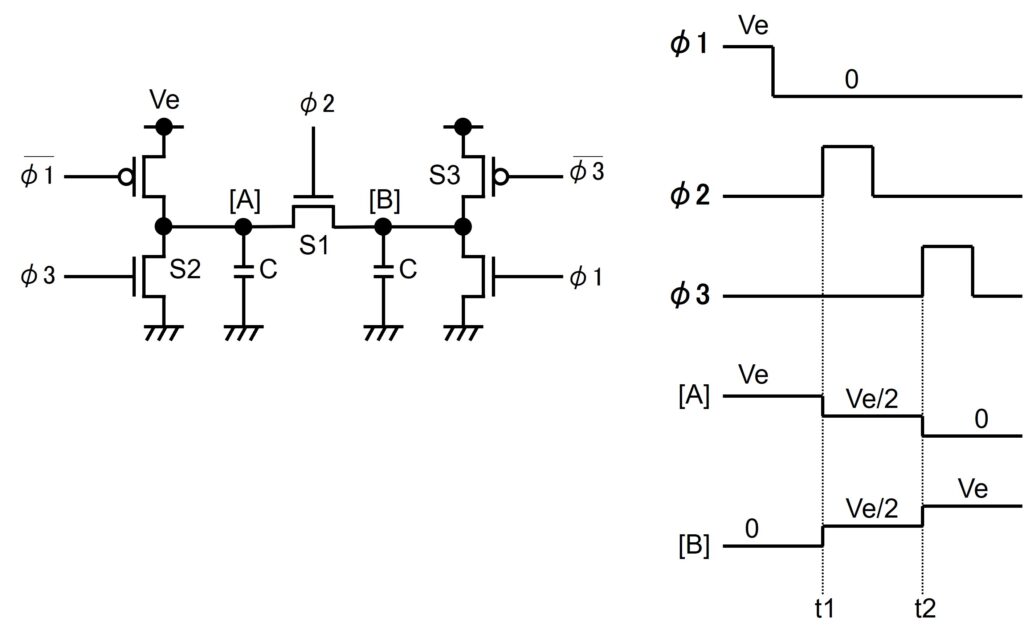
チャージリサイクリングのメカニズム
メカニズムを簡単に説明します。
ノード[A]、[B]を各々Ve→0、0→Veにする場合、t1のタイミングでS1をONさせ電荷分配によってノード[A]および[B]をVe/2にします。次いでt2のタイミングでS2(GND側スイッチ)、S3(電源側スイッチ)をONし、ノード[A]、[B]を各々目標のVe/2→0、Ve/2→Veにします。この過程において、ノード[A]の放電する電荷の1/2はノード[B]を充電するために再利用されている。このチャージリサイクリング技術によって、消費電力を1/2に低減する事ができるわけです。
チャージリサイクリング技術の強誘電体メモリ応用例
さらに、図17にこの技術を強誘電体メモリ(FeRAM)へと応用した事例を示します。従来強誘電体メモリは、セルプレート線に容量値の大きい強誘電体メモリセルが接続されており、その充放電時の消費電力が大きな問題でした。
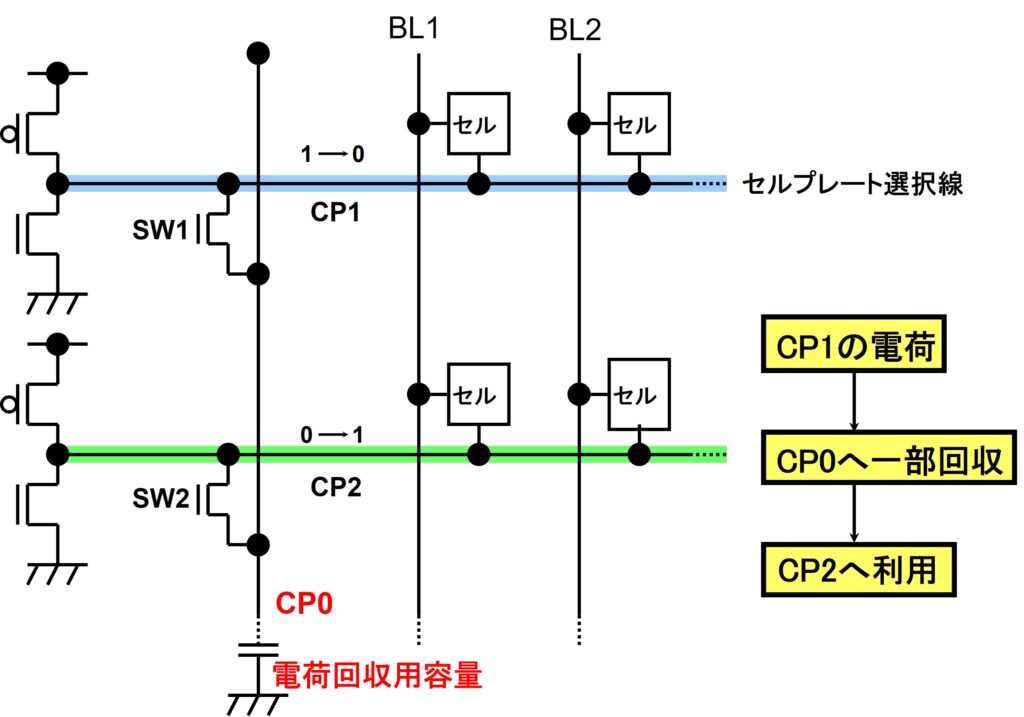
メモリアクセスによってセルプレート選択線CP1=“1”(選択)からCP2=“1”へ切り換えるとき、まず、電荷回収用容量線CP0とCP1をSW1によってONさせ、CP1とCP0とを電荷分配させる。この時、CP1の電荷の一部がCP0へと転送されます。次にCP0とCP2をSW2によってONさせると、CP0の電荷の一部がCP2へ転送されます。
すなわち、放電すべきCP1の電荷の一部が、スイッチドキャパシタ動作によってCP1→CP0→CP2のパスで、充電すべきCP2で再利用することができるのですね。この時 CPn/CP0値を最適化すれば、およそ50%近い電荷再利用効率を得る事ができた、という事例になります。
「容量の充放電」がポイント
ポイントは、CMOSLSIで使われる電力のほとんどが「容量の充放電」で費やされている事実です。ですから、チャージリサイクリングのような「容量の充放電」をコントロールする技術は低消費電力化において重要な技術です。言い換えるなら、LSI回路設計における低消費電力化とは「ある大きな容量のノードを放電する時、その電荷をどこか他のノードに利用できないか?」が本質といっても過言ではありません。(その解決策を考えるのがLSI技術者の面白いところでもありますね)
さて、システムLSIの低消費電力化技術についてはひとまず終え、次は高速化技術についてご紹介できればと思います。