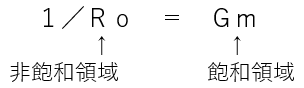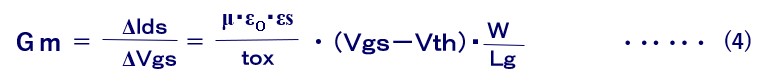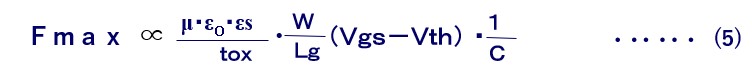こんにちは。今日はCMOS LSIの性能を上げつつ低消費電力化を実現する技術の1つをご紹介します。 前の記事「CMOS LSIの消費電力と動作周波数」をご覧になる方はこちら 低しきい値MOS技術とは 低電源電圧領域におけるCMOS LSIの高速動作の最大のポイントはVthです。Vthを低くできれば高速化を図れるはずですが、実際はサブスレッシュホールド・リーク電流という別の問題によって効果は制限され […]
続きを読む
こんにちは。今日はCMOS LSIの性能を上げつつ低消費電力化を実現する技術の1つをご紹介します。
前の記事「CMOS LSIの消費電力と動作周波数」をご覧になる方はこちら
低しきい値MOS技術とは
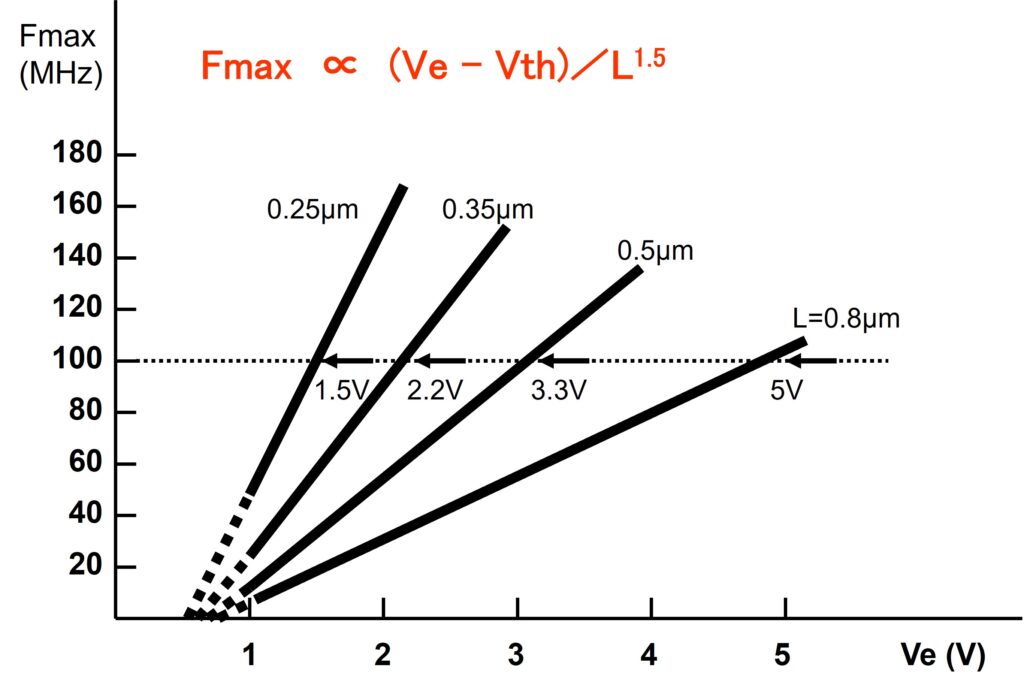
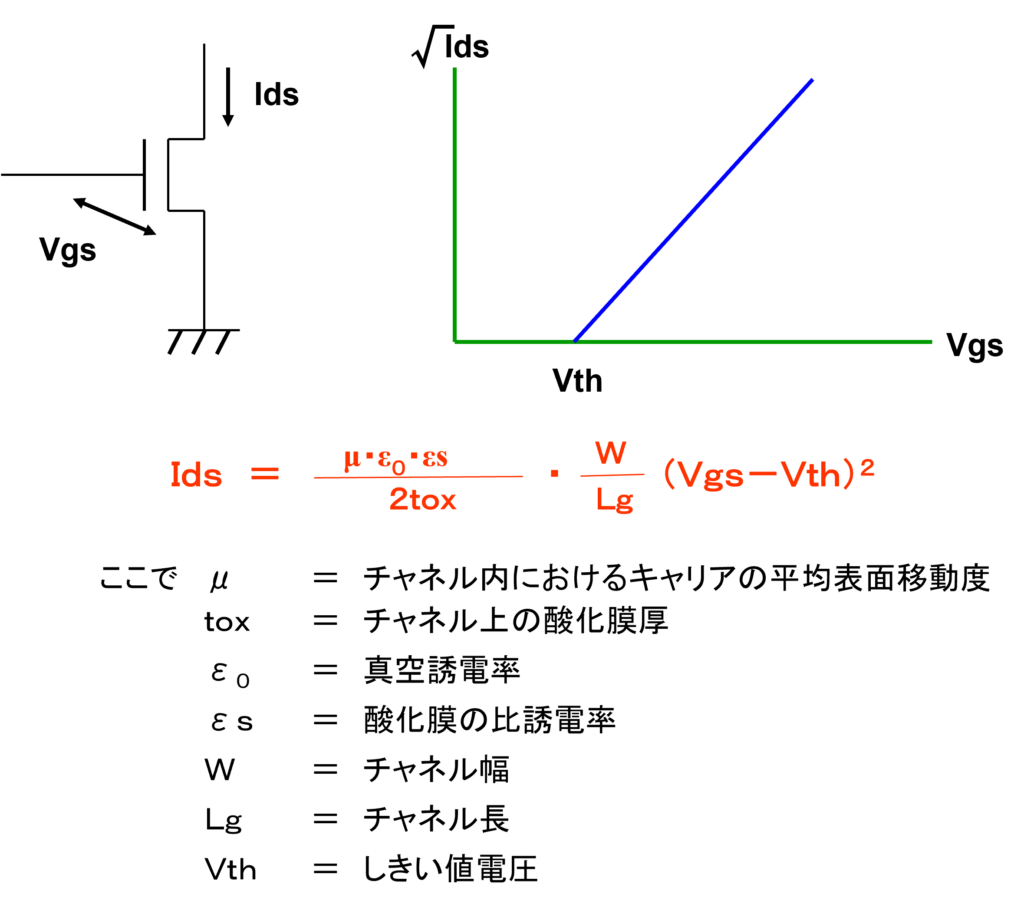
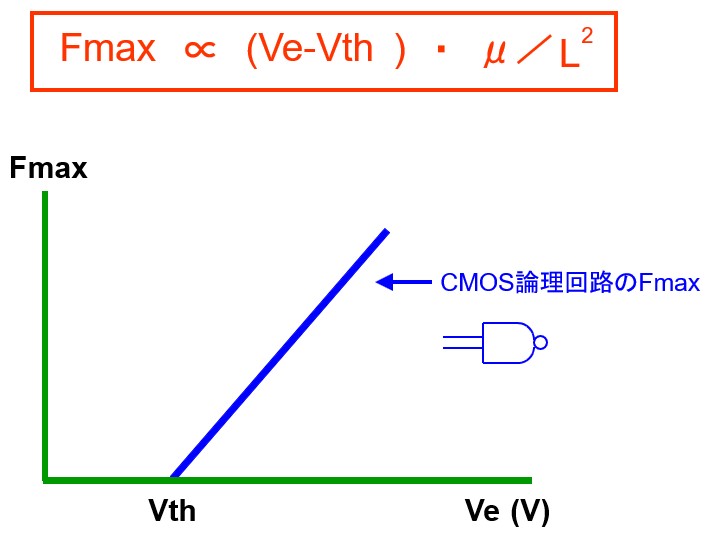
低電源電圧領域におけるCMOS LSIの高速動作の最大のポイントはVthです。Vthを低くできれば高速化を図れるはずですが、実際はサブスレッシュホールド・リーク電流という別の問題によって効果は制限されてしまいます。一般にSi-MOSでは、Vthを0.1V下げると、そのOFF時のリーク電流が1桁増えます。Vthを下げられる限界はプロセス製造ばらつきを考慮すると0.3~0.4Vです。
ところが近年、論理回路のVthを0.1~0.2Vのレベルまで下げて回路の高速化を図り、低電圧化により増大するリーク電流を回路的工夫によって解決する 技術が開発されました。それぞれ 「 MT-CMOS (M ulti-T hreshold CMOS )」 「 ダイナミック・ウェル・バイアス法」と呼ばれます。
MT-CMOS (M ulti-T hreshold CMOS )
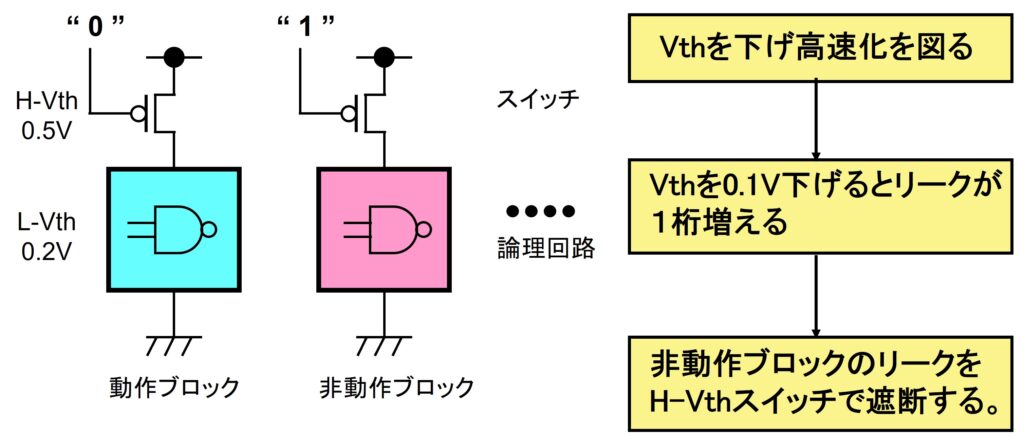
MT-CMOSの原理図を図7に示します。
0.1~0.2Vレベルの低しきい値(L-Vth)MOSで構成されたLSI論理回路を機能に応じていくつかの回路ブロックに分け、各ブロックとLSI電源との間に、0.4~0.5Vレベルの標準しきい値MOS(H-Vth)の電源スイッチを挿入します。
図7 MTCMOS (NTT、NEC、日立 他)
MT-CMOSでは、パワーマネジメントによって動作ブロックと非動作ブロックに制御され、動作ブロック【青】の(H-Vth)MOSスイッチのみONさせます。動作ブロック【青】の論理回路は(L-Vth)MOSで構成されており、低電圧にもかかわらず高速動作します。一方、非動作ブロック【赤】の(L-Vth)MOSで構成される論理回路には、サブスレッシュホールド・リーク電流が流れるものの、(H-Vth)MOSスイッチによって遮断され、悪影響を抑え込みます。
動作ブロック【青】の論理回路のサブスレッシュホールド・リーク電流は依然存在するのですが、信号処理に応じてノードを充放電する動作電流に比べて小さいので無視できます。加えて、動作ブロックの電源スイッチによる電圧ドロップ(IRドロップ)についても、各ブロックのサブ電源ラインが持つ大きなノード容量による低域フィルタ的な働きにより抑圧され、ほとんど問題とならないです。
このMT-CMOS技術は、90nm以降の先端プロセスを待たずに、1Vレベルの低電源電圧における高速動作を実現する有力な手段となりました。
ダイナミック・ウェル・バイアス法
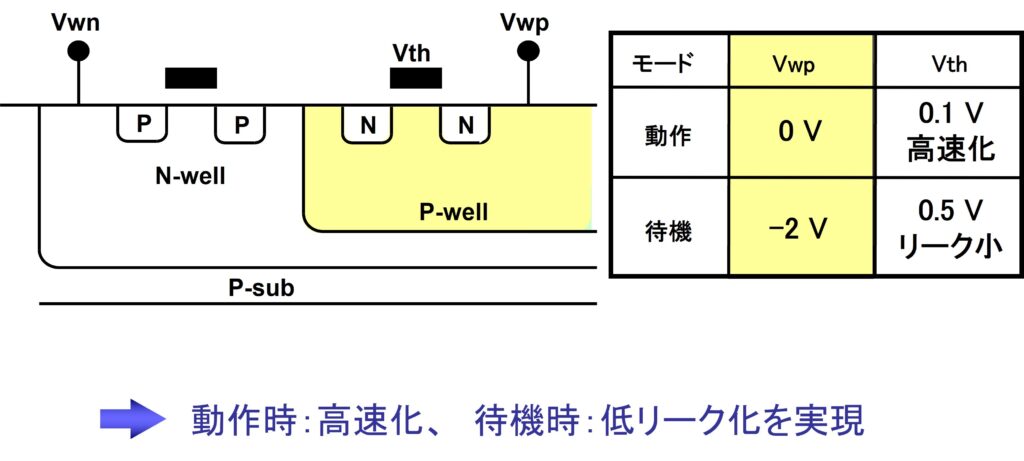
ダイナミック・ウェル・バイアス法は、LSI論理回路を低しきい値(L-Vth)MOSを用いて構成し、回路の高速化を図る方法です。MT-CMOSと同様、非動作(スタンバイ)時における(L-Vth)MOSを介したサブスレッシュホールド・リーク電流が問題となるのですが、これを、ソースーウェル間を深くバイアスする事によりVthの値を大きくしてリーク電流を抑圧するのが、ダイナミック・ウェル・バイアス法のコンセプトです。この原理図を図8に示しました。
図8 ダイナミック・ウェルバイアス制御(東芝)
LSIを機能に応じていくつかのブロックに分け、各ブロックごとのウェル・バイアスを動作ブロックについては浅く(Vth→小)して動作を高速化し、待機ブロックは深く(Vth→大)してリークを押さえる。MT-CMOSとは違うVthのコントロール技術で、サブスレッシュホールド・リーク電流を抑圧しつつ低電源電圧高速動作を実現できる。
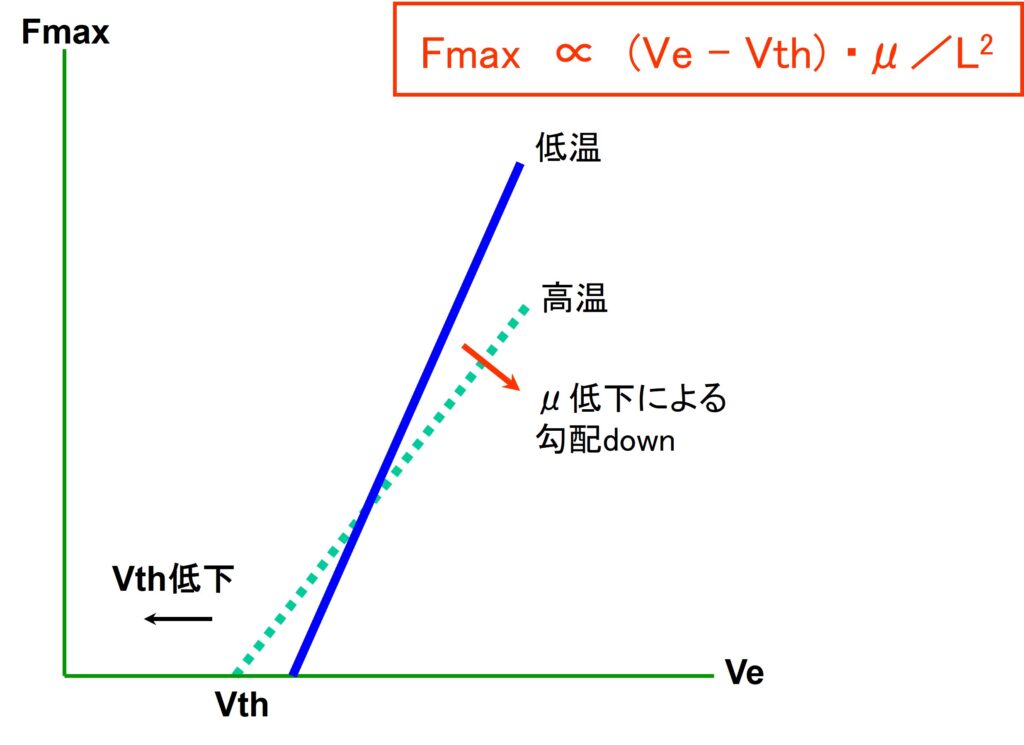
冒頭でVthの制御では、プロセス製造ばらつきの考慮が必要と申し上げましたが、1Vレベルの低電源電圧動作時では、プロセス上のばらつきが動作周波数に与える影響が大きく、Vthが高い方向へ大きくバラツクと最大動作周波数が極端に低下してしまいます。ダイナミック・ウェル・バイアス法では、動作ブロックにおいて、ウェル・バイアスをVthのバラツキに適応してコントロールすれば、安定した所望のVthが得られ、低電源電圧高速動作を実現する事ができます。確立後しばらくこの方法はプロセス、温度、電源電圧等の変動において有力な手段でありました。
次は、活性化領域を最小化して省電力化を狙った技術をご紹介します。
曽根田 光生
電気通信大学卒業。ソニー(株)で画像信号処理用LSI、ビデオメモリ、A/Dコンバータ、MPEG2チップの設計/商品化、低消費電力技術及びプレイステーション用セル回路設計などに尽力し、システムLSIに関連する特許を240件出願。ISSCC及びVLSI Circuitsのプログラム委員を歴任。工業所有権協力センター(財団)にて特許の先行技術調査を担当。
2023年ディー・クルー・テクノロジーズ(株)に入社。特許、半導体設計、技術人材育成等の業務に携わっている。
閉じる