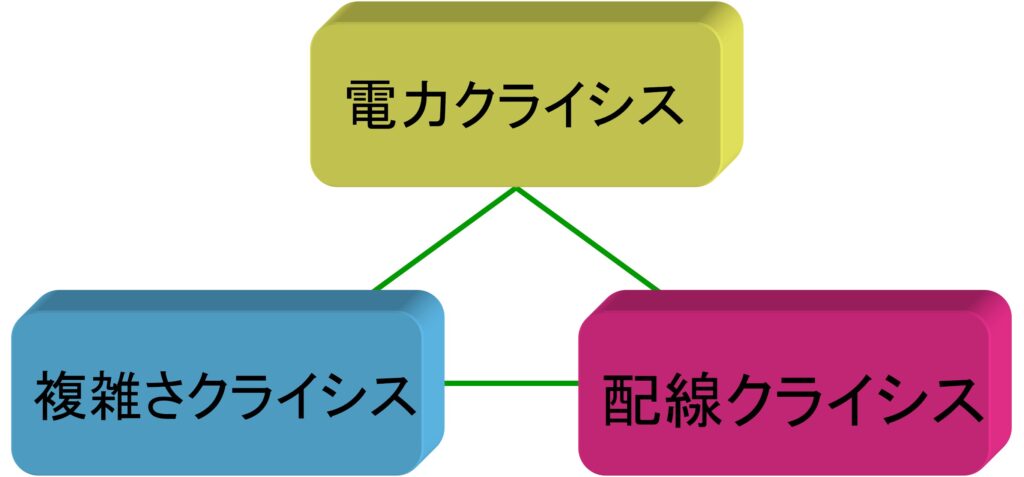
3つの技術クライシス
システムLSI(SoC)に搭載するトランジスタの集積度を上げる(トランジスタを小さくし、たくさん並べる)ほどLSIの演算性能は上がるのですが、同時に「電力」「複雑さ」「配線」の3つの主要な技術的課題に直面します。各クライシスに対する原因、課題、対策について簡単にまとめました。
電力クライシス
電力クライシスとは消費電力と性能のバランスの問題です。システムLSIのトランジスタを集積して動作周波数を上げれば処理能力が上がりますが、同時に消費電力が増加し、バッテリーサイズ、リーク電流の発生、発熱に影響します。逆に動作周波数を落とせば処理能力は低下します。
LSIの微細化に伴って、特にドレインーソース間のリーク電流増加が大きな問題になっています。これに対してFin-FETやGAA-FETのような近年の新しいトランジスタ技術はリーク電流減少に寄与します。さらに最近はDVS(Dynamic Voltage Scaling)やDVFS(Dynamic Voltage & Frequency Scaling)といった新しいパワーマネジメント手法を導入することで、動的に電力を管理し、さらに細かく消費電力を最適化することも始まっています。電力クライシスに対処するためには、このように回路、アーキテクチャー、システム、アルゴリズムの工夫が必要となります。
複雑さのクライシス
複雑さのクライシスとは、SoCのトランジスタ数が増加するにつれて、設計の複雑性が増大することです。例えばAppleの A17proは190憶トランジスタを使用し、3nm GAA-FETプロセスを採用しています。これは、100人✖1年の設計工数を必要とするほどの複雑さです。こうした設計の複雑性の増加は、設計時間の増加、コストの増大、およびエラーの可能性の増加を招きます。
複雑さのクライシスに対する対策としては、Cベース(高位合成)やIPベースの設計化です。これらを進めることで、設計プロセスを自動化し、設計効率を向上させることができます。また、ドメイン特化型プラットフォームの構築は、設計資産を効率的に再利用し、開発時間とコストを削減することができます。
配線クライシス
配線クライシスとは、システムLSIの論理回路ブロック同士をつなぐクリティカルパスによる信号遅延のことです。トランジスタの微細化がすすみ、今はシステムLSIの中で非常に多くの論理回路ブロックを置くことができるようになりました。しかし先に論理ブロックを並べてから配線する従来の「P&R(Place & Route)」の設計方法ですと、配線長がどんどん長くなりがちです。特にクリティカルパスが長くなることは致命的で、信号遅延による非効率な回路となってしまいます。
配線クライシスに対する対策として、クリティカルパスについてはP&R設計ではなく先に配線レイアウトを最適化する「R&P(Route & Place)」による設計が最も重要です。加えてSI(Signal Integrity)やPI(Power Integrity)に起因するクロストークやIRドロップに対する対策も効果的です。さらに新しい技術としてチップ間の遅延時間を大幅に短縮する3次元積層化技術も有効な手段として期待しています。
最も重要なのは電力クライシス対策
LSIのトランジスタ微細化の大きな流れの中で、私は電力クライシス対策が最も重要なカギと考えていて、技術開発に取り組んでまいりました。そこでまずシステムLSIで私が省電力化に対して取り組んだことをご紹介し、次にこれから特に有望と考えうるアーキテクチャーとして、DVFS, DVS 等について順次ご紹介しようと思っています。