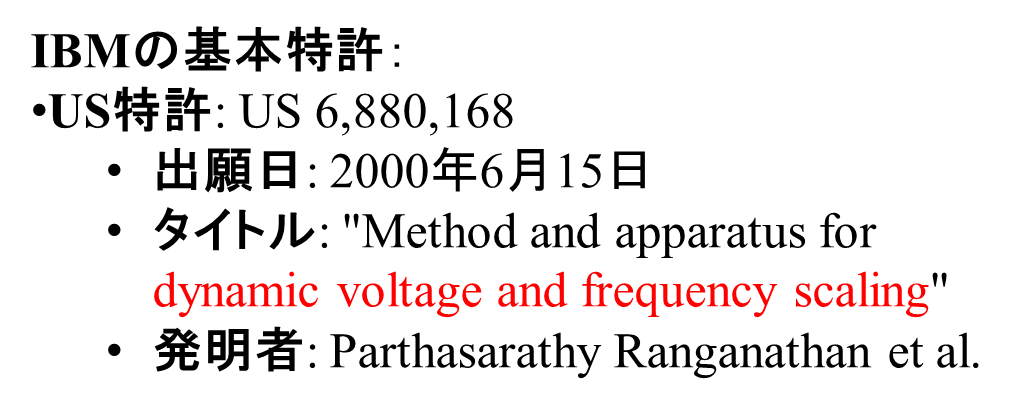こんにちは。今日は、DVFSの元となった、動的電圧スケーリング(DVS)開発の背景をお伝えします。 前回の記事はこちら 動的電圧スケーリング(DVS)とは? 近年マーケットからLSIの低消費電力化が強く求められていく時代でありながら、従来SoCのSPECで規定されていた設計補償動作電圧では、本来欲しい動作電圧に比べて大きなマージンを含んだ電圧が必要となり、それが低消費電力化の障害となっていました。 […]
続きを読む
こんにちは。今日は、DVFSの元となった、動的電圧スケーリング(DVS)開発の背景をお伝えします。
前回の記事はこちら
動的電圧スケーリング(DVS) とは?近年マーケットからLSIの低消費電力化が強く求められていく時代でありながら、従来SoCのSPECで規定されていた設計補償動作電圧では、本来欲しい動作電圧に比べて大きなマージンを含んだ電圧が必要となり、それが低消費電力化の障害となっていました。
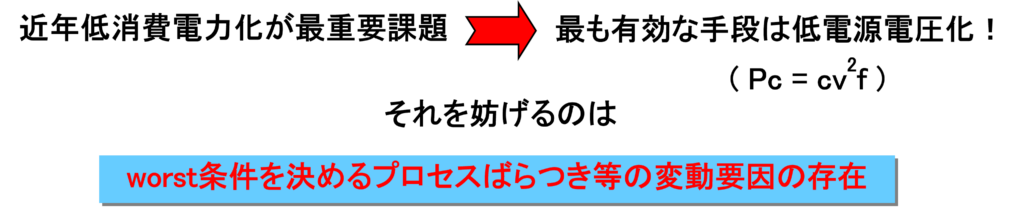
そこでDVSが登場したのです。一言で言うと、DVSは、SoC内のクリティカルパスが動作するぎりぎり最小の電源電圧Vddを適応的にSoCに供給する技術 です。どういうことか分かりやすくするため、動的電圧スケーリング(DVS)開発の背景を図示しました。
図1 動的電圧スケーリング(DVS)開発の背景
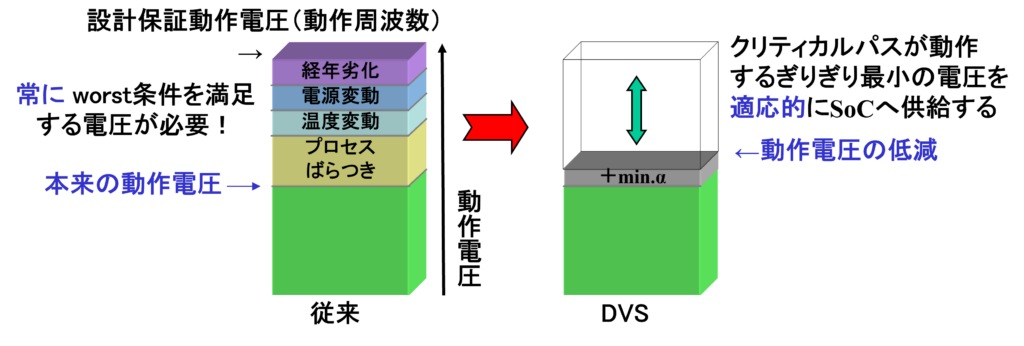
左側が従来の設計補償動作電圧、右側がDVSです。SoCにおけるプロセスばらつき、温度変動、電源電圧変動、経年劣化等のworst条件を満足させるため、本来必要な動作電圧に比べ無駄に大きかった動作保証電圧の閾値を、右のDVSではクリティカルパスが動作するギリギリ+αの最小電圧をアダプティブにSoCに供給するため、動作電圧を低減し省電力化に貢献できます。
レプリカによるクリティカルパス監視がDVS技術の肝
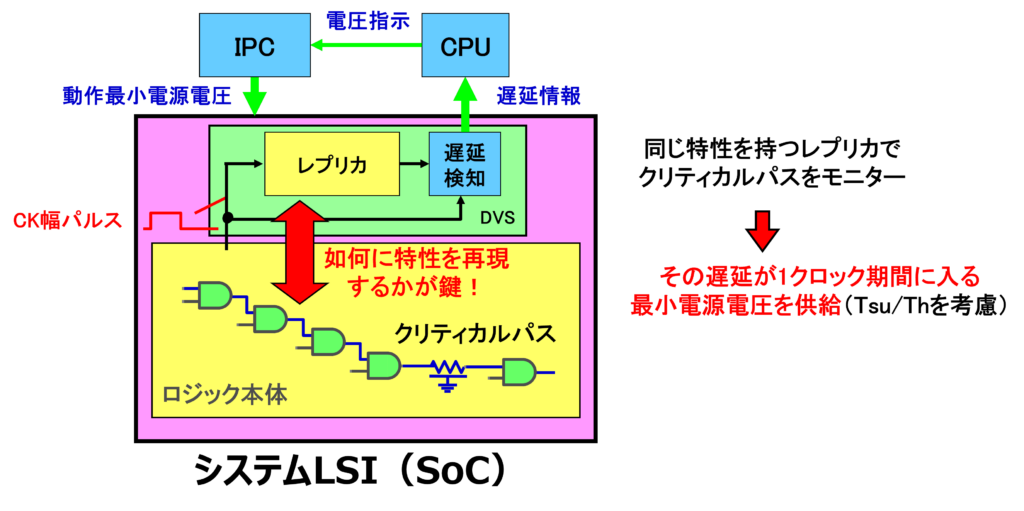
図2にプロセスばらつき/温度変動等に対応したDVSを紹介します。SoC内部のクリティカルパスと同等の遅延時間を有するレプリカ回路を用意し、レプリカの遅延時間がクロック1周期内に入るギリギリ最小の電源電圧をSoCに供給します。
図2 DVS(プロセスバラツキ/変動対応)SoCの構成(特開2000-216337を参考に弊社作成) 無論電源電圧供給ではTsu/Thを考慮しますが、こうしたレプリカによるクリティカルパスモニターが、設計マージンの最小化を可能した結果、低消費電力化が実現しています。
DVSの効果
DVSは従来型に比べどの程度省電力化に効果があるのでしょうか?
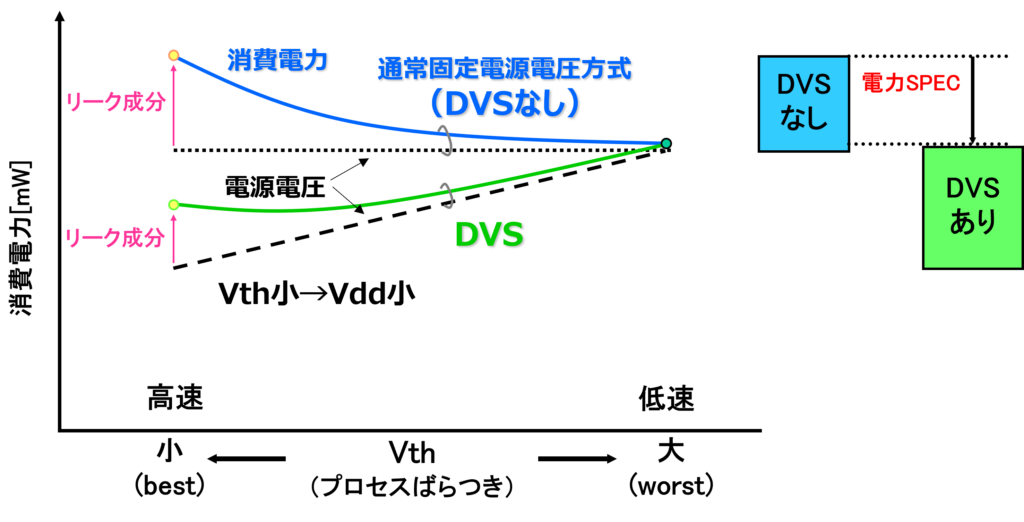
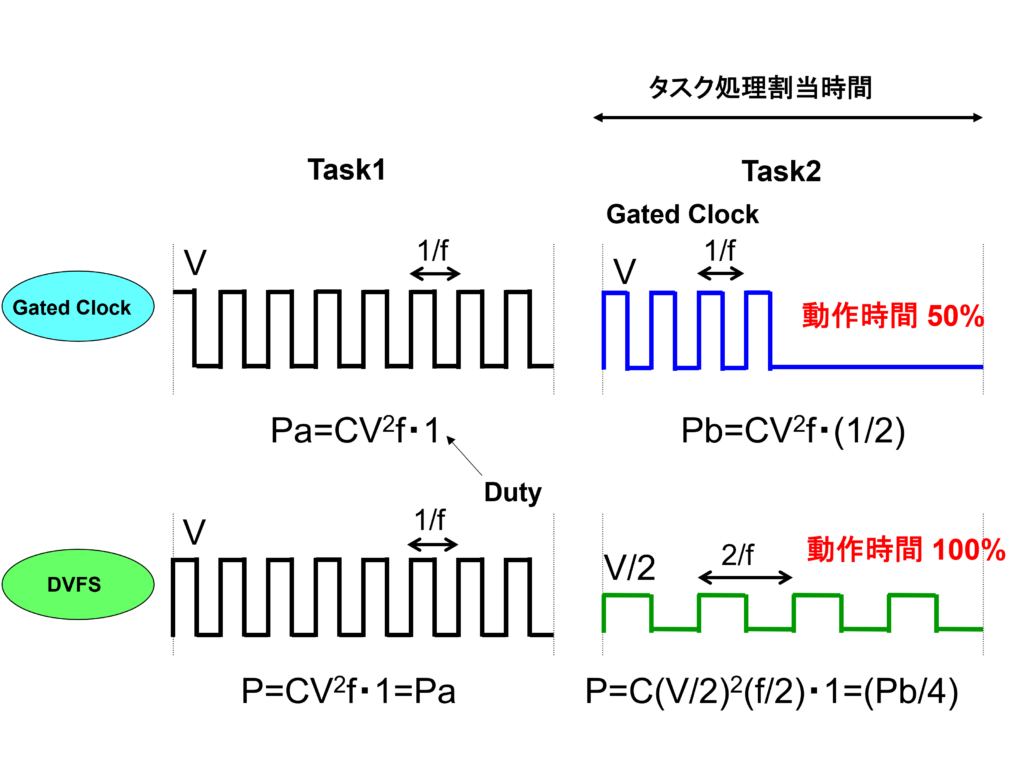
図3にDVSの効果を示します。近年はMOS トランジスタの微細化により、サブスレッシュホールド・リーク電流が無視できなくなります。従来の固定電圧方式では、低Vthサンプルでリーク電流の増大に伴う消費電力増加が大きな問題になります。一方でDVSを採用すると、低Vthであっても回路の高速化を図れるため、電源電圧を低減でき、低消費電力化が図れますので、製品の消費電力SPEC低減に貢献できます。
MOS 動作周波数 Fmax ∝ ( Vdd - Vth )・ μ/ L 2 微細化するとリーク電流増大→リークが問題となるVth小サンプルをDVSで補償
図3 DVS有り、無しにおける消費電力効果の比較
DVFSによる最小電源電圧供給
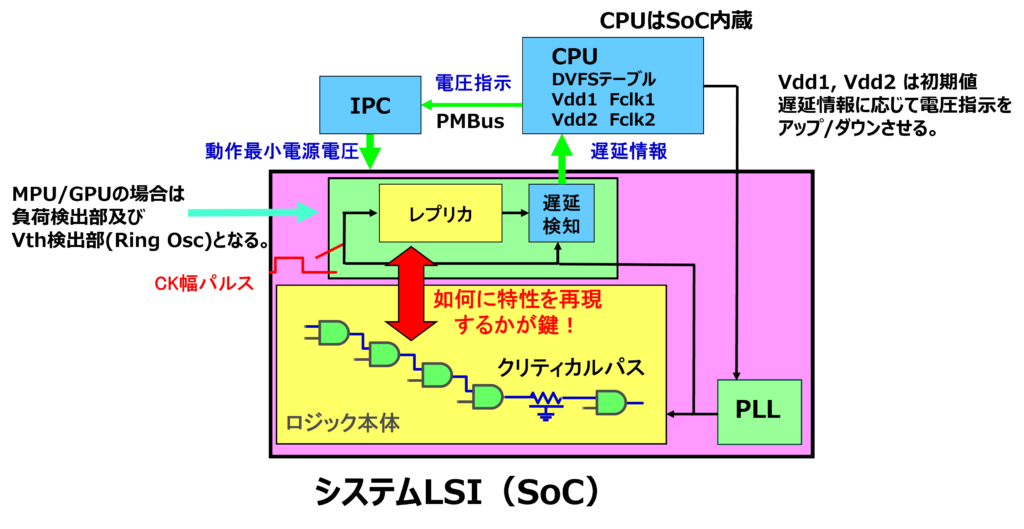
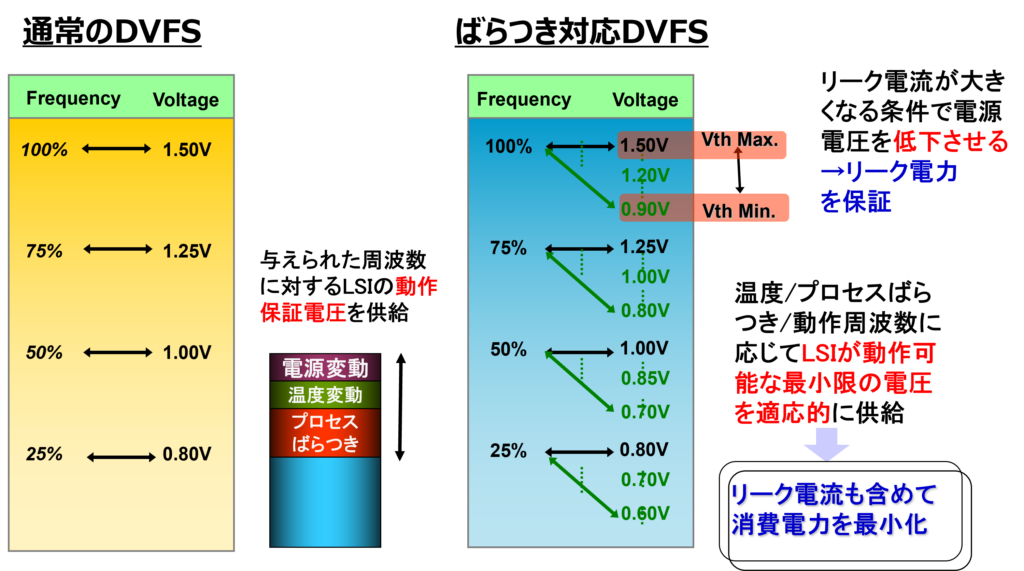
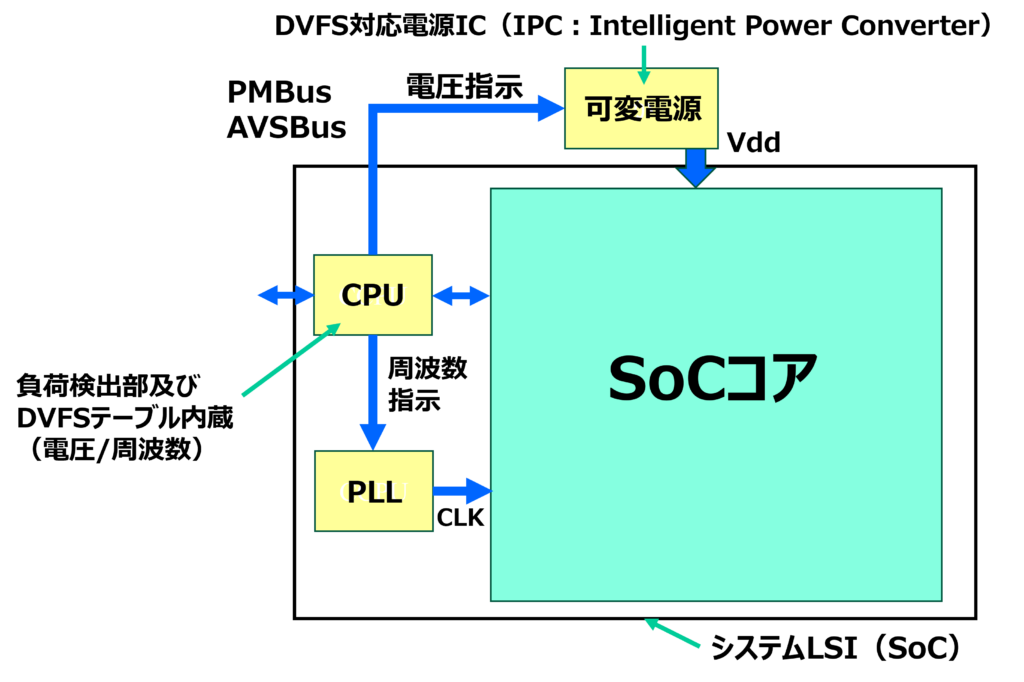
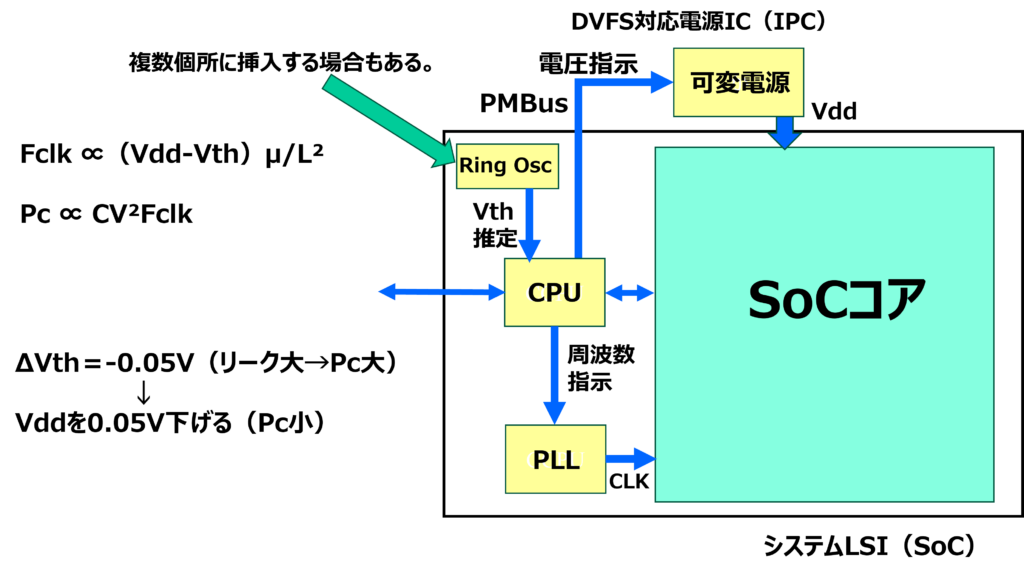
DVSとDVFSの違いは、プロセスばらつき等のworst条件において、電圧だけでなく「動作周波数」も考慮に入れて、その瞬間の最小電源電圧を供給できる点にあります。図4にばらつき対応DVFSのブロック図、図5にばらつき対応のDVFSによる最小電源電圧供給を示します。
図4 ばらつき対応DVFSのブロック図
DVFSは、プロセスばらつき、温度変動、そして現在の動作周波数に応じて、SoCが動作する最小限の電圧を適応的に供給します。SoC内蔵のCPUがレプリカ回路からの遅延情報を解析して電圧指示に変えるのですが、MPU/GPUなどの高度なプロセッサの場合は、負荷検出部およびVth検出部(Ring Osc)からの情報がリアルタイムにフィードバックされます。
図5 ばらつき対応のDVFSによる最小電源電圧供給
ばらつき対応DVFSであれば、動作周波数に応じ、リーク電流が大きくなる条件(Vthが小さい個体など)において電源電圧を下げることで、リーク電力をスペック内に保証します。すなわち、Worst条件に応じて動的にLSIが動作可能な最低限の電圧を供給することで、リーク電流を含めたトータル消費電力を最小化できるのです。
DVFS技術を支える知財:基本特許からバラツキ補償への進化
今日、当たり前のようにSoCに搭載されているDVFS技術ですが、その進化の歴史は知財(特許)の変遷にも色濃く反映されています。ここでは、この革新的な技術を支えてきた主要な特許について解説します。
1. DVFSの基本コンセプトを確立した先駆的特許
DVFSの根幹である「処理負荷に応じて電圧と周波数を管理する」というアイデアは、1990年代末から2000年代初頭にかけて大手半導体メーカーによって提唱されました。
【DVFS 基本特許】
Intel(US 6,185,598): 1999年に出願されたこの特許は、低消費電力かつ高性能なマイクロプロセッサにおける動的な電圧・周波数管理の基本を定義した、非常に著名な特許です。IBM(US 6,880,168): 2000年に出願され、プロセッサの動作中に適応的にパフォーマンスと電力を調整する手法が記載されています。
これらの基本特許が、現代のモバイルデバイスやサーバー用CPUにおける省電力制御の礎を築いたといえます。
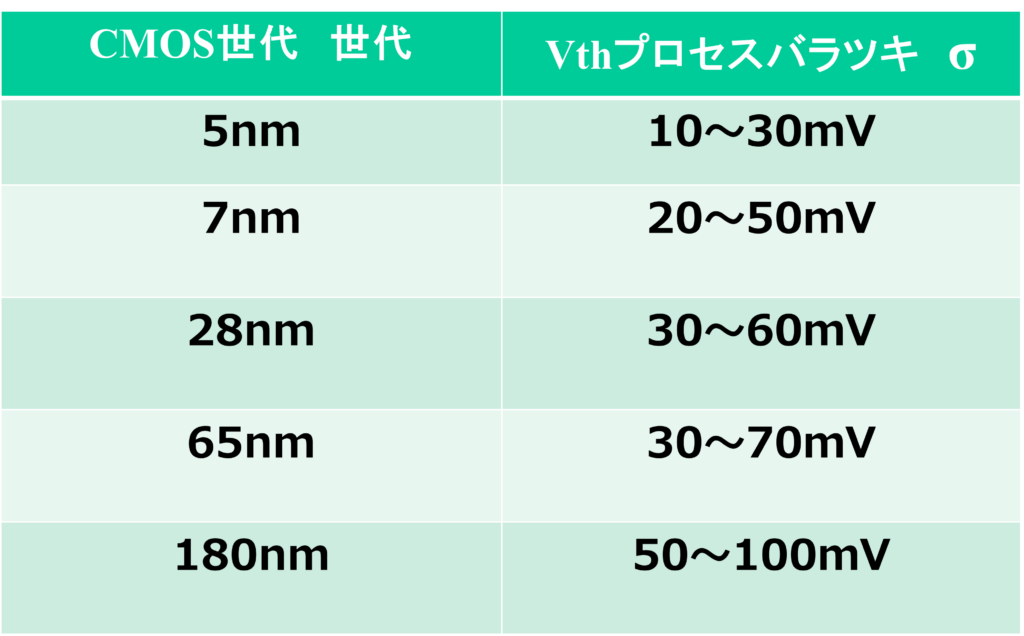
2. プロセスバラツキ対応による技術の精緻化
基本コンセプトの確立後、微細化の進展に伴って「個体差や環境変化をいかに吸収するか」という、より高度な制御に関する特許が登場し始めました。
【DVFS(プロセスばらつき対応特許)】
Intel(US 8,751,875): プロセスばらつきを考慮したDVFS技術を提供し、個々の集積回路の特性に基づいて動的に電圧と周波数を調整する技術です。IBM(US 8,799,830): 温度とプロセスばらつきの両方を考慮したDVFS技術を提案し、チップの動作環境に応じて最適な電圧と周波数を動的に設定する技術です。
このように、特許のトレンドを見ても、単なる「負荷への対応」から、「製造上の物理的なバラツキという限界を、設計技術で乗り越える最適化」へと、技術の力点が移り変わってきたことがわかります。
まとめ
最後に DVFS のまとめを示します。
1.プロセッサ系のMPU/GPU/SoCでは、素子バラツキ対応を含めたDVFSが幅広く使われている。 2.DVFSは負荷状態に応じて、動的に電源電圧とクロック周波数を制御する。 3. 素子バラツキを考慮したDVFSは、特に微細プロセスにおけるリーク電力削減に大きな効果を発揮する。 4. 基本技術からバラツキ補償への変遷に見られる通り、DVFSは今後、汎用プロセッサのみならず各種カスタムSoC(ASIC)においても不可欠な技術となっていく
いかがでしたでしょうか。この記事がLSIの低電力化における皆様のご理解の一助に慣れればうれしいです。
電気通信大学卒業。ソニー(株)で画像信号処理用LSI、ビデオメモリ、A/Dコンバータ、MPEG2チップの設計/商品化、低消費電力技術及びプレイステーション用セル回路設計などに尽力し、システムLSIに関連する特許を240件出願。ISSCC及びVLSI Circuitsのプログラム委員を歴任。工業所有権協力センター(財団)にて特許の先行技術調査を担当。
2023年ディー・クルー・テクノロジーズ(株)に入社。特許、半導体設計、技術人材育成等の業務に携わっている。
閉じる