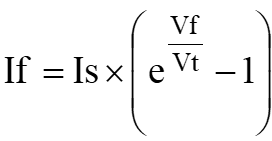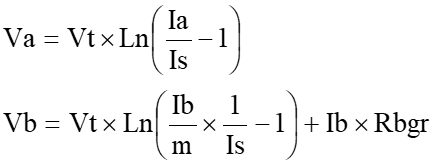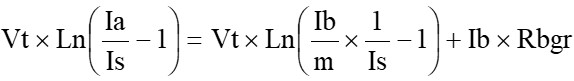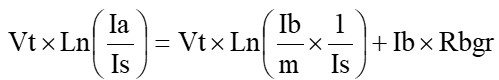システムインテグレーター(SIer)やソリューション企業にとって、クライアントからの要望は多岐にわたります。最近の技術トレンドであるAIやIoTの普及に伴い、データを活用して業務価値を最大化し、新たなビジネスモデルを構築したいというニーズが急増しています。しかしながら、データ処理の遅さや秘匿性の確保といった課題は、クライアントの生産性向上のボトルネックとなっています。こうしたニーズに対して、SIe […]
続きを読む
システムインテグレーター(SIer)やソリューション企業にとって、クライアントからの要望は多岐にわたります。最近の技術トレンドであるAIやIoTの普及に伴い、データを活用して業務価値を最大化し、新たなビジネスモデルを構築したいというニーズが急増しています。しかしながら、データ処理の遅さや秘匿性の確保といった課題は、クライアントの生産性向上のボトルネックとなっています。こうしたニーズに対して、SIerやソリューション企業の提案として有効な「ハードウェアアクセラレーション」についてご紹介します。
どんな種類のハードウェアアクセラレーションがあるのか?
クライアントが速度に関して課題を挙げるとき、高速処理のためのハードウェア導入(ハードウェアアクセラレーション)が有効な場合があります。
ここでは主なハードウェアアクセラレーションの手法について比較してみましょう。
1. CPU(Central Processing Unit)
CPUは一般的なプロセッサで、小数の高性能コアを持つため、シリアル処理に強み があります。オフィスアプリケーションや軽量なウェブブラウジングなど、一般的な作業に利用されますが、並列処理には限界があります。
2. GPU(Graphics Processing Unit)
GPUは、多数のコアを持つため、大量のデータを並列処理 するのに優れています。主にグラフィックスの生成や機械学習に利用されることが多く、処理速度を大幅に向上させられます。TensorFlowやPyTorchなどのライブラリからも活用され、大量データの高速処理を実現します。
3. FPGA(Field-Programmable Gate Array)
FPGAはプログラマブルなハードウェアで、特定の処理に特化した効率的な処理 が可能です。特にリアルタイムデータ処理や医療イメージングに用いられ、高速かつ柔軟なソリューションを提供します。
4. ASIC(Application-Specific Integrated Circuit)
ASICは特定のアプリケーション向けに設計された集積回路で、高速で効率的な処理 が可能です。ただし、設計や初期投資に高コストが必要で、柔軟性に欠ける点もあります。
ハードウェアアクセラレーションの選択で何を重視すべきか? これらのハードウェア技術はそれぞれ異なる強みを持っています。最適な選択とは、求められる性能、コスト、開発リソースによって異なるため、各シナリオに応じた評価が不可欠です。いずれの対策でも、投資には限りがあるため、コストパフォーマンスを考慮した導入が求められます。
1. CPU(Central Processing Unit)
アーキテクチャは 一般的なプロセッサであり、少数の高性能なコアを持つ。複雑なタスクを順次処理するのに優れている。シリアル処理に強いが、並列処理能力は限定的で 一般的なコンピュータアプリケーションや制御タスクに利用されます。例えばシングルスレッド性能が求められるため、高速なプロセッサが必要なWordやExcelなどのオフィスアプリケーションはCPUで動作します。また、ウェブブラウザはHTML、JavaScript、CSSなどの軽量な処理を行うため、CPUの能力が重要です。さらに、家電製品や自動車の制御に使われる 組み込みシステムやIoTデバイスな制御システムでは、一定の処理をシリアルに実行する必要があります。
2. GPU(Graphics Processing Unit)
CPUの通常処理では重すぎる演算や並列タスク処理を、GPU(Graphics Processing Unit)に肩代わりさせ、効率良く管理・実行する技術です。CPUと連携して、重要な処理や重い処理、またタスクの依存関係を考慮して、効率よく順序だててGPUへ割り当てる手法をGPUスケジューリングと呼びます。
GPUは多数のコアを持っており、同時に多くのスレッドを処理することができるため、大量のデータ処理や並行処理に向いています。用途としては、ゲームや映画のグラフィックスの生成に使用され、高速な3Dレンダリングを実現します。例えばNVIDIAのGeForceシリーズは、リアルタイムグラフィックスレンダリングに特化しています。また、大量のデータを並列処理する能力を活かして、機械学習・ディープラーニングにおいて、トレーニングプロセスを加速します。例えばTensorFlowやPyTorchなどのライブラリでは、GPUを活用することでモデルのトレーニング時間を大幅に短縮します。また膨大なデータセットを高速に処理して分析するため、HadoopやApache Sparkなどのフレームワークと組み合わせてビッグデータで利用されます。
2. FPGA(Field-Programmable Gate Array)
アーキテクチャ: プログラマブルなハードウェア、「FPGA」を用いて、特定の処理の重いタスクを効率的に処理する方法です。四則演算や命令分岐などGPUでは効率的に処理できない特定のアルゴリズムに対するパフォーマンスを最大化できます。
音声認識や画像処理、通信でデータをリアルタイムにデジタル信号処理するために使用されます。また、超音波診断装置やMRI装置など、高速かつ柔軟な処理が求められる医療イメージングに使用されます。また高速取引(HFT)では、取引アルゴリズムをFPGA上で実行することで、ミリ秒単位での取引が可能になります。このような特定の計算処理に非常に効果的ですが、設計にはある程度の時間とFPGAにおけるハードウェア・ソフトウェアの専門知識が必要です。しかしそうした専門家による工夫次第ではスパコンを凌駕する演算能力を発揮させることができることがFPGAの大きな特長です。
3. ASIC
ASIC(Application-Specific Integrated Circuit)は、特定のアプリケーションや用途向けに設計された集積回路です。特定のタスクに最適化して設計されているため、一般的なプロセッサに比べて処理速度が非常に高速です。これにより、高度な演算やデータ処理が迅速でかつ省電力です。特定の機能に特化した設計のため、必要な回路だけを集約でき、チップのサイズを小さくすることができます。
一方ASICの開発には高額な設計費用と時間がかかり、小ロット生産に向かないので、少量生産や汎用性の低い用途には不向きです。またASICは一度設計すると変更が難しく新たな機能追加や改善ができないので、設計段階での柔軟な設計変更にも対応しづらいです。さらに設計から製造までには時間がかかるためスピードが求められる設計開発には不向きです。このようにASICは特定のアプリケーションに対して非常に優れた性能を発揮しますが、設計コストや柔軟性の面でのトレードオフに注意する必要があります。
ハードウェアアクセラレーションで最も重視すべきポイント それぞれのハードウェアアクセラレーション技術は、特定の用途や要件に応じて強みが異なります。最適な選択は、求められる性能、コスト、開発リソースなどによって異なるため、具体的なニーズに応じて評価することが重要です。これらの用途を理解することで、プロジェクトや研究において最適なコンピューティングリソースを選択する際の指針となります。ただしいずれの手段でも、クライアントが重視するのは、秘匿性が担保されていること、高速化が実現できること、それでいてリーズナブルなコストであることは重要な選択ポイントとなります。
ディー・クルー・テクノロジーズのFPGAソリューション 弊社には極めて専門性の高いFPGA設計ができるエンジニアが在籍しております。演算処理の圧倒的な高速化を求める方に、2タイプのハードウェアアクセラレーションでデータ処理の未来を切り開くソリューションをご提供できます。クライアントが直面しているデータ処理の課題に対して、是非私たちの革新的なハードウェア及びファームウェアソリューションをお試しください。
1. 低コストでの導入
大規模な投資は不要。コスト効率の高いソリューションで、企業の利益を最大化します。
2. 高い秘匿性
データを社内で処理するため、セキュリティの確保が可能。機密性の高い情報を安心して扱えます。
3. 高速化の実現
大量かつ複雑なデータ処理において、従来の方法に比べて数倍から数十倍の処理速度を誇ります。
⓵ FPGA高速化ソリューション FPGAで難解な科学計算を高速で解きたい。元々柔軟性やカスタマイズ性の高いこのハードウェアをベースにし、演算処理の実行は弊社開発の専用プログラムで表現した「ソフトウェアとハードウェアの融合」した方式です。このメリットは特定の計算タスクに特化したハードウェアプログラム構成により、GPUよりも高速な処理速度を実現。カスタマーに要求されるリアルタイムでのデータ処理が可能です。
② QALMOⓇ 最先端の疑似量子アニーリング技術を駆使し、FPGAで複雑なデータセットの最適化を実現します。従来のアルゴリズムでは対処しきれない問題に対して、効率的かつ迅速な解を提供します。
ブログ管理者。ディ―・クルーの情報発信を担当。
閉じる