
無人のTOFセンサー画像とリアルタイムのTOFセンサー画像を比較することで、人の位置や状態を判断できるのであれば、AIも同様にそれを判断できるはずです。この考えを基に、シンプルなAIモデルを開発しました。
前回の記事はこちら
AIモデルの仕組み
このAIモデルは、以下の3つの状態を検出できるように設計されています。
- 空の個室 – TOFセンサーの測距値から人が存在しないことを検出し、トイレが使用されていないことを示します。
- 使用中の個室 – TOFセンサーの測距値から立っているまたは座っている人を検出し、トイレが使用中であることを把握します。
- 転倒した人 – TOFセンサーの測距値から床に倒れている状態を検出し、緊急事態であることを示します。これは迅速な対応を必要とします。
さらに、より高度なケースとして、トイレに座ったまま体調不良になった場合などには、タイムアウト検出機能を設けました。具体的には、「トイレに座ったまま15分以上動きがない」といった条件でこの異常を検知し、見守りアラートを発することが可能です。
PoCにおけるAIモデルの構成図
今回のAIモデル開発は非常にシンプルなものに徹しました。以下にPoCにおけるAIモデルの構成図を示します。
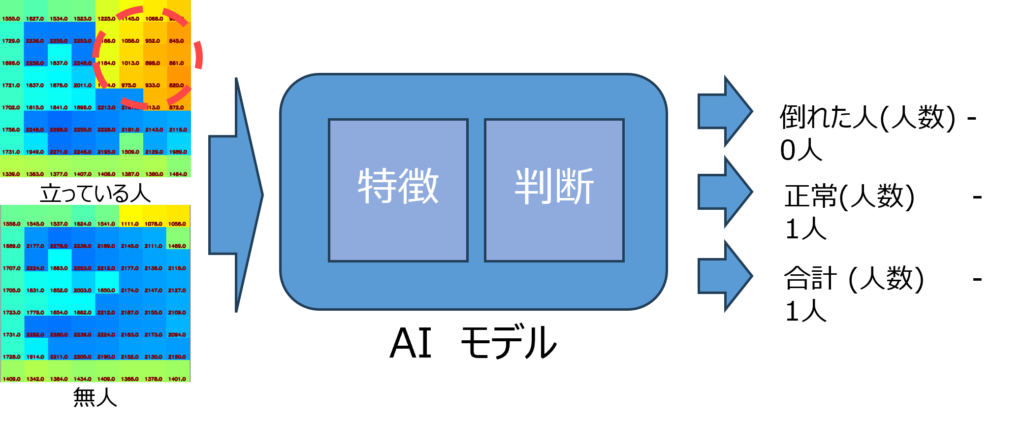
AIモデルの入力(左端)
このモデルには、以下の2つの入力があります。
- リアルタイムのTOF画像 ‐ 状態(立っている、座っている)を示す画像。
- 無人のTOF画像 – トイレが空いている状態を示す画像。
AIモデルの構成(中央)
このAIモデルは、次の2つのパートから成っています。
- 特徴 抽出パート – 画像から特徴情報を抽出します。
- 判断 パート – 抽出された特徴情報をもとに状態を判断します。
AIモデルの出力(右端)
また、出力は下記の3つです。
- 転倒状態の合計人数 – 床に倒れている人の数。
- 正常な状態の合計人数 – 立っているまたは座っている人の数。
- 検出された合計人数 – 検出された全ての人の数。
AI モデル学習を実行する
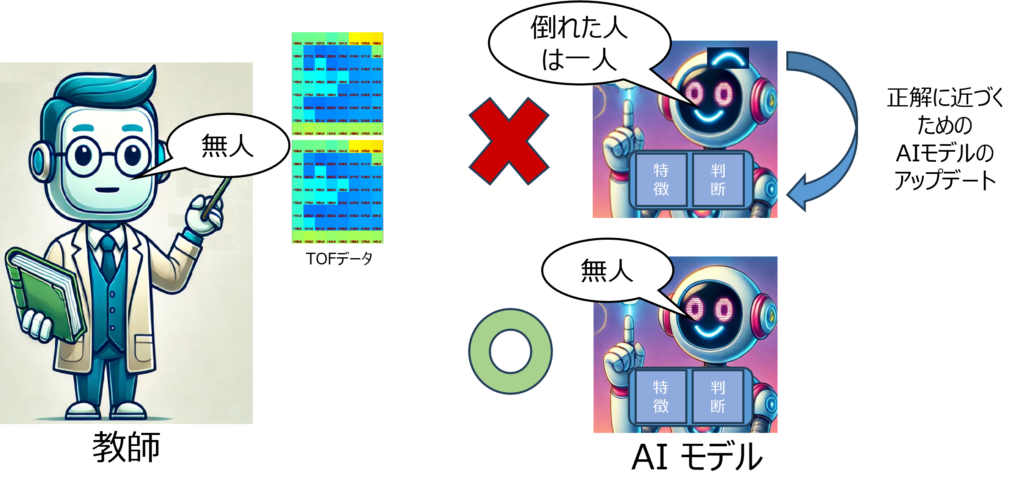
AIモデルは教師あり学習を用いて学習されます。モデルを学習させるためには、入力データと出力データの2種類のデータが必要です。教師あり学習とは、正解を逐次教えることで学習を行う方法です。
- 入力TOFデータ – TOFセンサーの測距画像データ。
- ラベル(出力)– 出力データとして、検出された合計人数、正常な状態の合計人数、転倒状態の合計人数を使用します。
AIモデルが学習するステップは?
AIモデルの学習ステップは以下の通りです。
- TOFセンサーの測距画像をAIモデルに入力し、AIモデルの判断結果を正解データと比較します。
- AIモデルを更新し、正解に近い判断ができるように調整します。。
このように、プロセスはシンプルなのですが、賢いAIモデルを生み出すためにはこのプロセスになんと、数万枚の画像「データ」とそれ以上の反復学習が必要になる場合があります!
実用的なAIソリューションを作ることは挑戦ですが、最大の課題はAIモデルそのものではなく、「データ」です。
次回は、私がどのようにしてトイレのためのAI学習用「データ」を収集したのか、その方法についてお聞かせいたします。