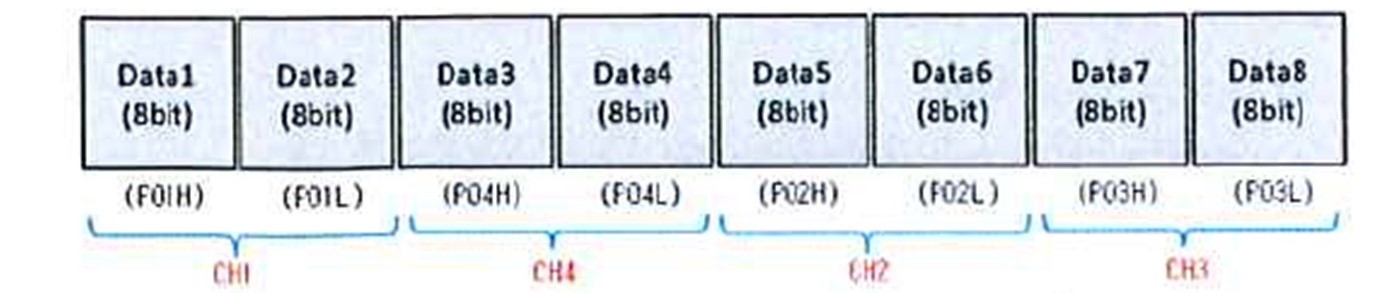
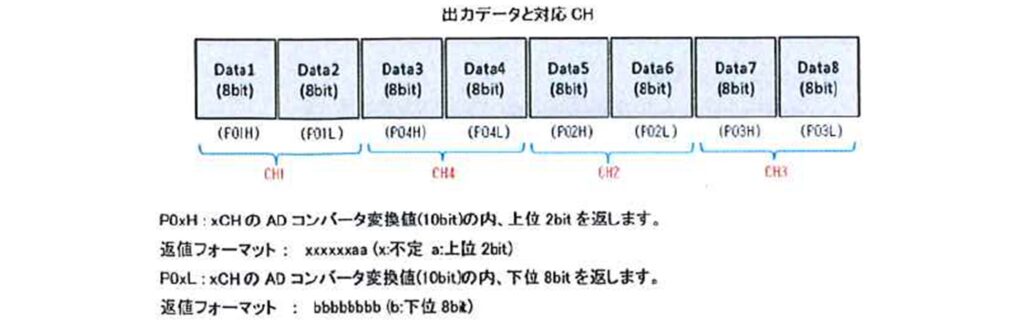
では、さっそくセンサを動かしてみましょう!

## ハードウェア
- ML8511使用紫外線センサーモジュール(ML8511)
ML8511使用紫外線センサーモジュール: オプトエレクトロニクス 秋月電子通商-電子部品・ネット通販 (akizukidenshi.com)
久しぶりの半田付けで少しドキドキしました(苦笑)

感覚忘れないように定期的にしないとダメですね。頑張ります!
- Arduino Leonardo
こちらは、以前のテーマ↓で使用したデバイスを流用しています。
- USBケーブル(Micro USB Type-B 2.0)
- Windows 11 PC
そして、手軽に紫外線を照射する装置も必要です。
- UV LED ネイルライト
これは、センサが紫外線に反応することを確認するために使用しました! 確認のために窓際や外に行くのも面倒なので、手元で確認できるものないかなーと探してみたところ、3COINSで発見!!
私も大好きなぷっくりツヤっとしたジェルネイルを硬化させるために爪に当てて使用するものです。これで税別300円とは今回使用するセンサよりもさらにリーズナブルです!
3COINSさん流石ですね。。
UVLEDネイルライト/and us | 3COINS(スリーコインズ)レディース | PAL CLOSET(パルクローゼット) – パルグループ公式ファッション通販サイト

## ハードウェア接続
以下の図のように実際に接続しました。
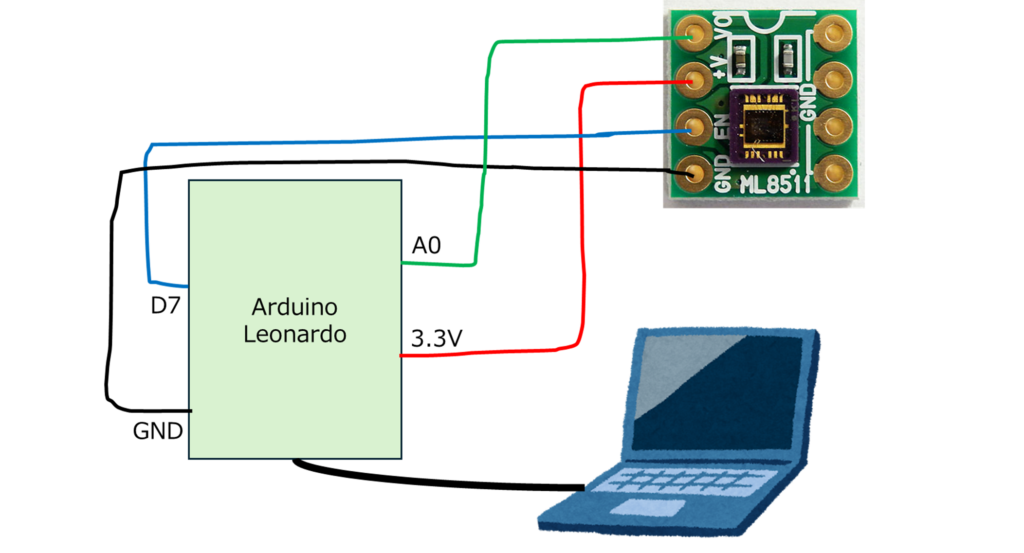
以上でプログラム実装前の前準備が完了です。
## プログラム実装
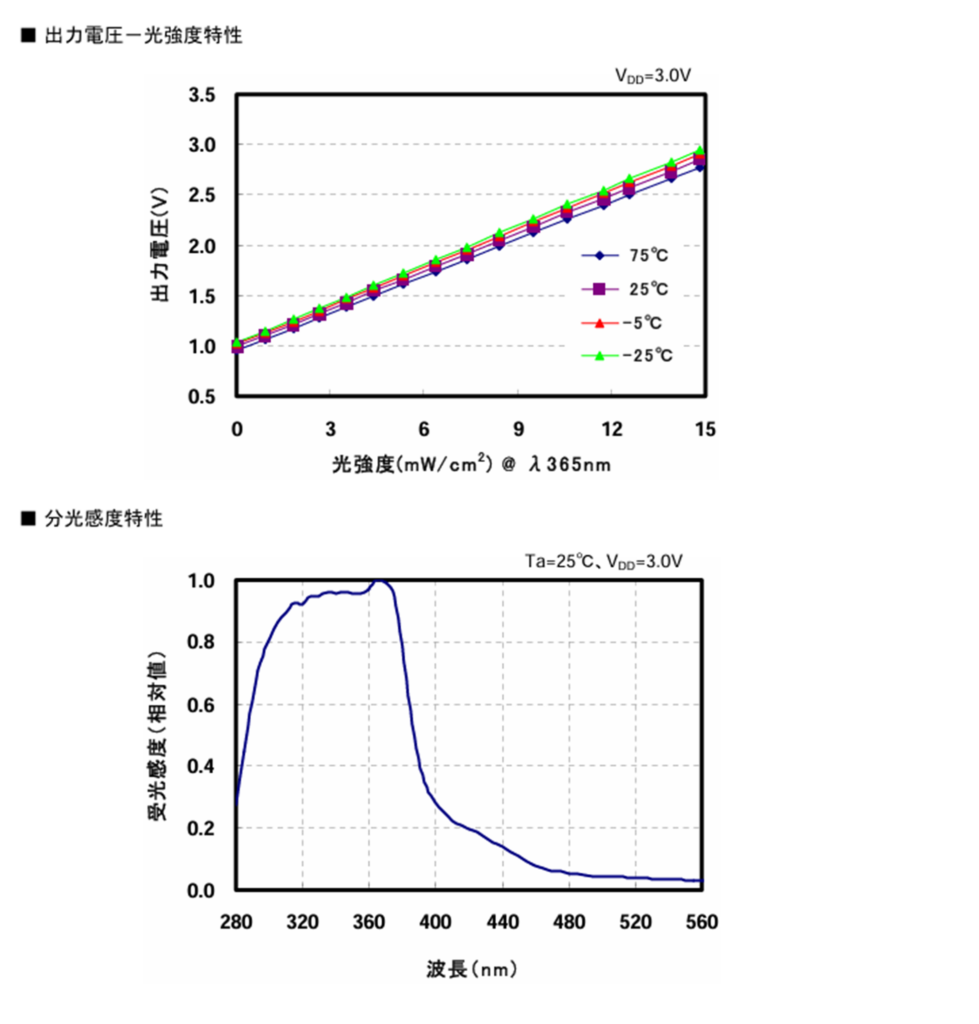
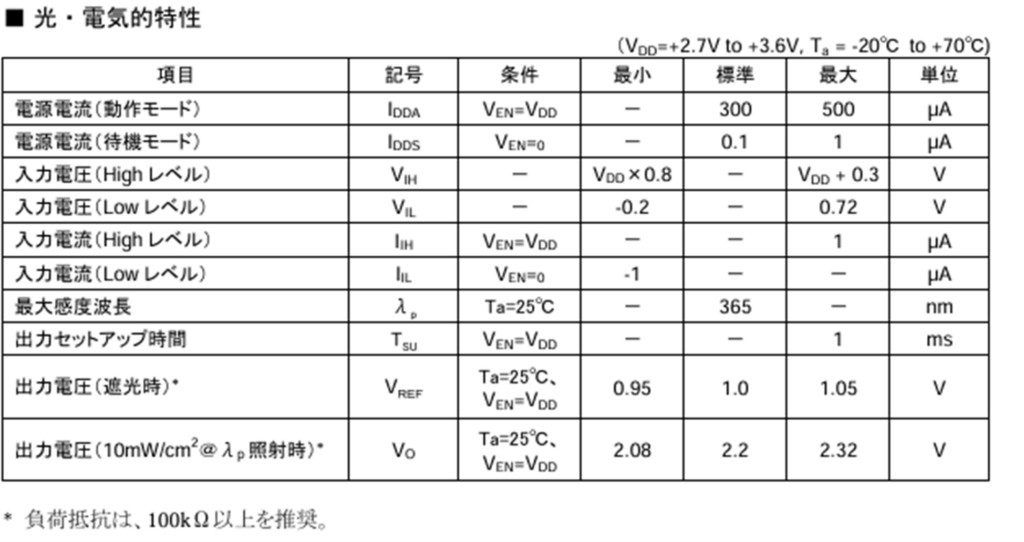
今回使用するセンサからはUV光強度に比例したアナログ電圧が出力されます。
なので、定期的にアナログ値を取得して電圧値に変化する処理を実装すればセンサの値は取得できそうですね。ただ電圧値だけでは紫外線が強いのかわかりづらいので、電圧値からUVインデックスを求めてPCに表示するプログラムを実装したいと思います。
計算方法ですが、アプリケーションノートML8511_UV.pdf (sparkfun.com)
に詳細に記載されていましたので、この方法で求めていきたいと思います。
Arduino側のプログラム動作手順概要:
- 初期設定
- PCとのHardwareSerial通信を開始
- センサのイネーブルピンにHigh出力
- 1secのタイマを開始
- タイムアウト時にセンサの出力ピンからアナログ値を取得
- 取得した値を電圧値に変換
- 電圧値からUVインデックス値に変換してシリアルで表示
Arduinoのツールに”Serial Plotter”というものがあり、シリアル出力した値をグラフ化してくれます。
簡単に状態変化をリアルタイムで確認できるので、かなり便利でした。
## センサ動作結果
UVライトのON/OFFとUVセンサのリアルタイムの状態変化が分かるSerial Plotterのグラフを一緒に動画にしてみました。
動画8秒あたりから、UVライトONするとすぐセンサは反応してくれています!! 👏
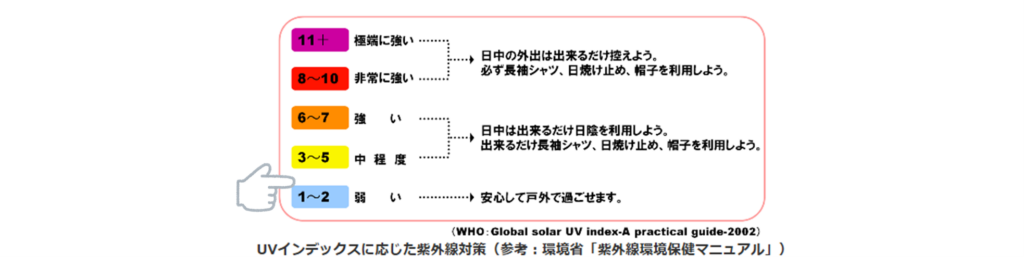
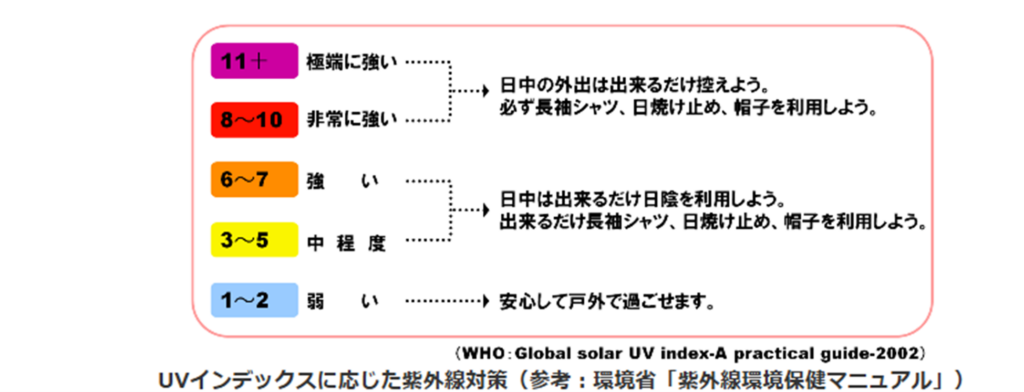
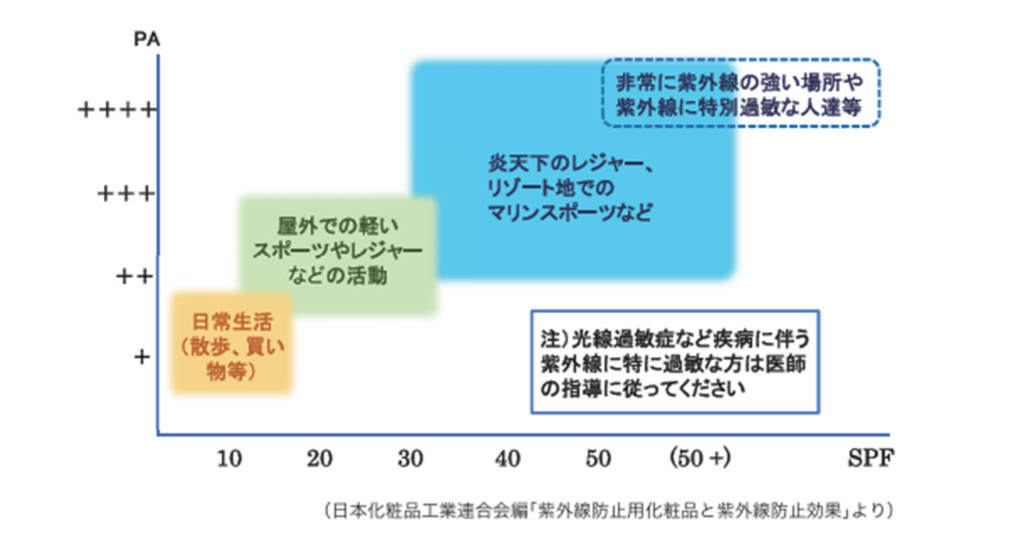
UVを照射するとUVインデックス約2.5~3のあたり、弱い➡中程度のあたりでグラフ表示されますね。
今回より出力が高いUV LEDネイルライトだと数値が変わるのか興味があります。今回は室内というのもあり補正をしてないのですが、アプリケーションノートによると環境によってUVインデックスからの補正が必要なようで、条件によって誤差がありそうです。
よくよく調べてみるとSerial Plotterのグラフは複数データの表示もできるようです。ただY軸の範囲は自動で変更されるようなので、値の範囲が異なる数字を表示するときは注意が必要そうです。
おっと、UVインデックスのリファレンスとなるデバイスを用意していないです。あーリファレンスをどうしよう。。。

あ!そうだ気象庁情報です!!
気象庁で紫外線情報(分布図)を出しているのです。ピンポイントではありませんが、実験している場所付近の値をリファレンスにすればある程度は使えそうに思います!
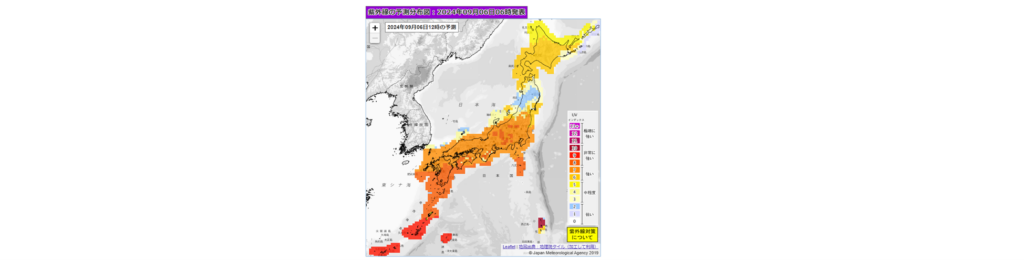
ちなみに気象庁紫外線情報のUVインデックスは11+が最高ではなく、さらに12や13+があるのですが、日本でしばしば12や13といった値が観測されるため、気象庁では実情に合わせて13+まで表示するそうです。恐るべし日本の夏!
さて、センサが動くことは確認できたので、次は外で実験する前にUVインデックスを無線で飛ばして確認できるように改造したいと思います!
外出先でPC+Arduinoを常に一緒に持ち歩いて計測するのも大変なので(トホホ)
それではまた!