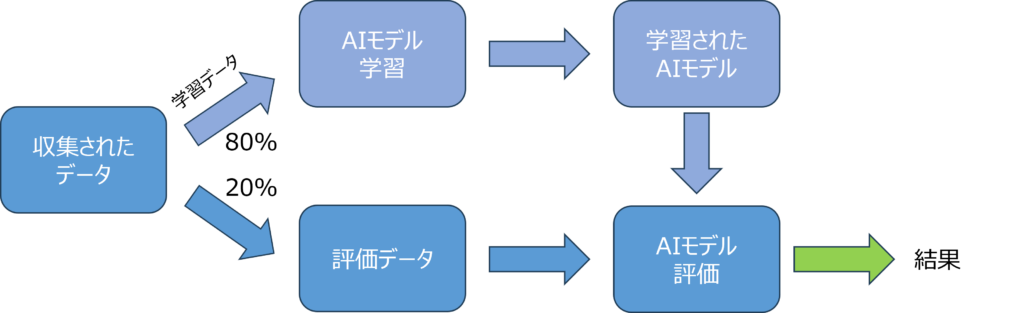
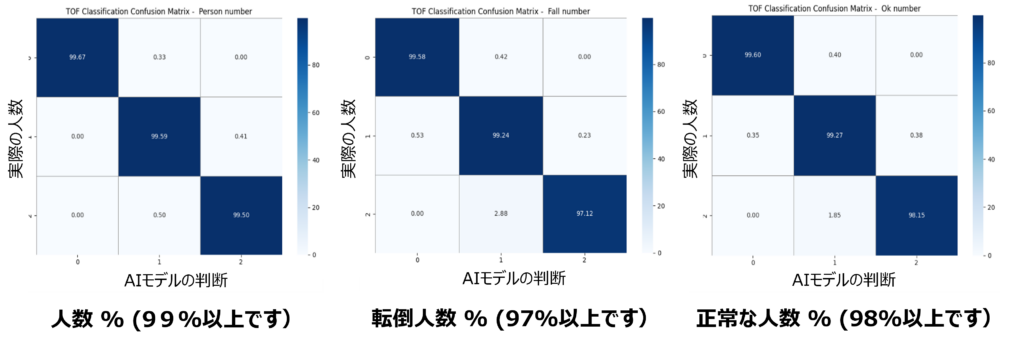
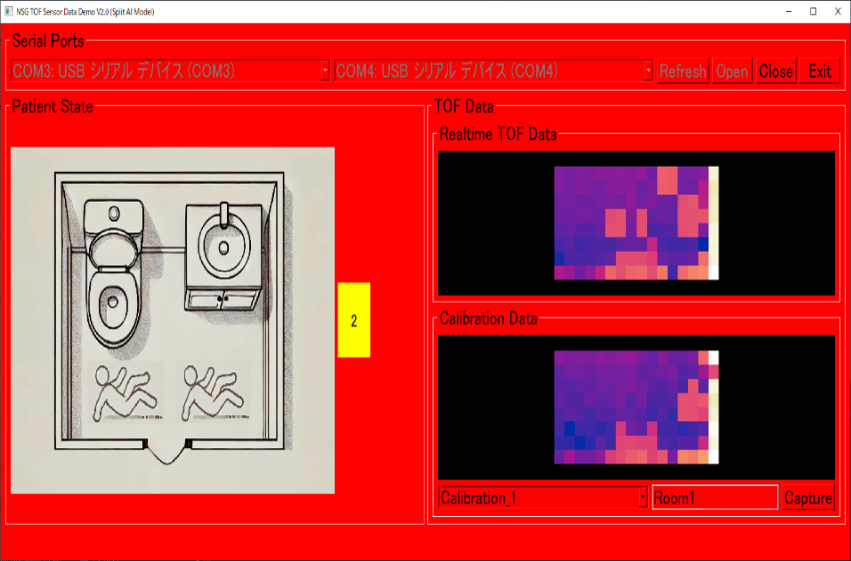
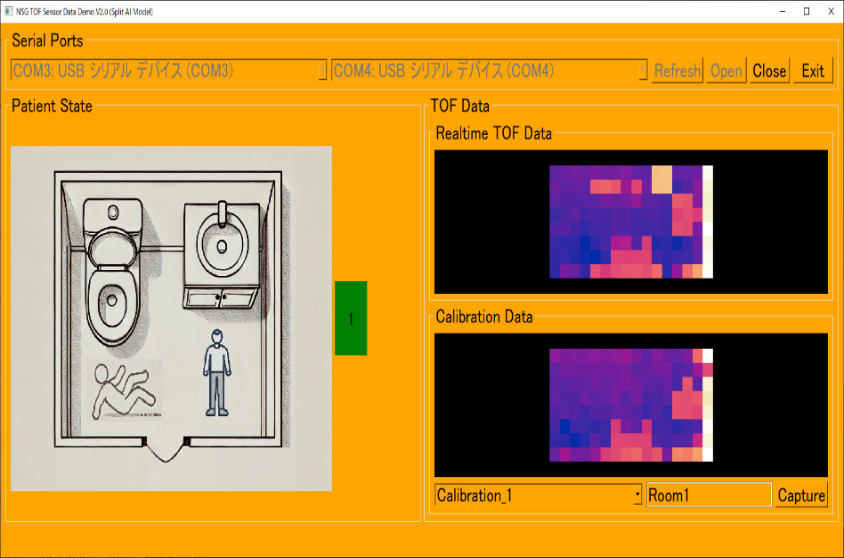
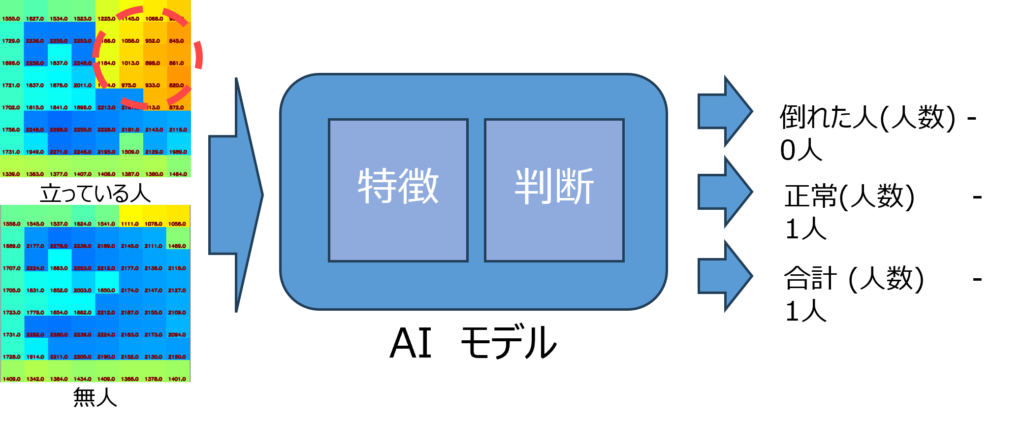
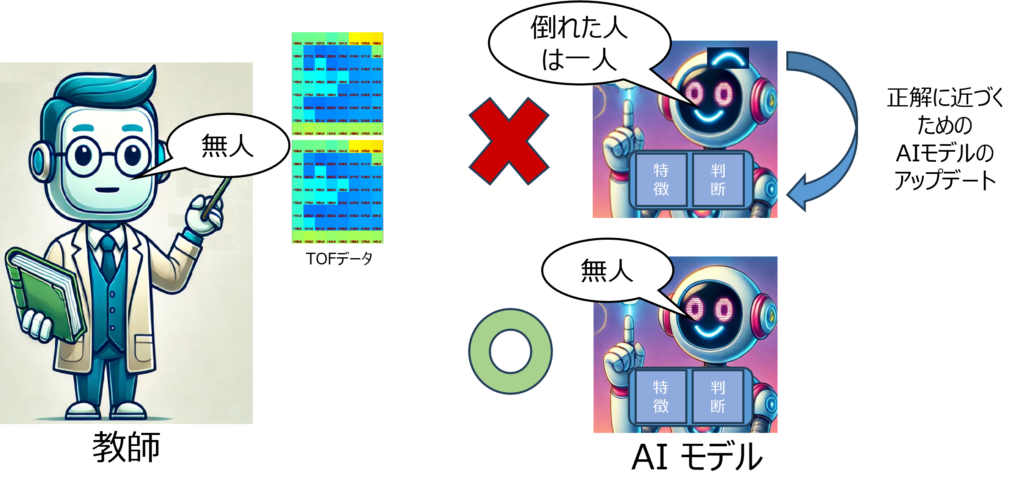
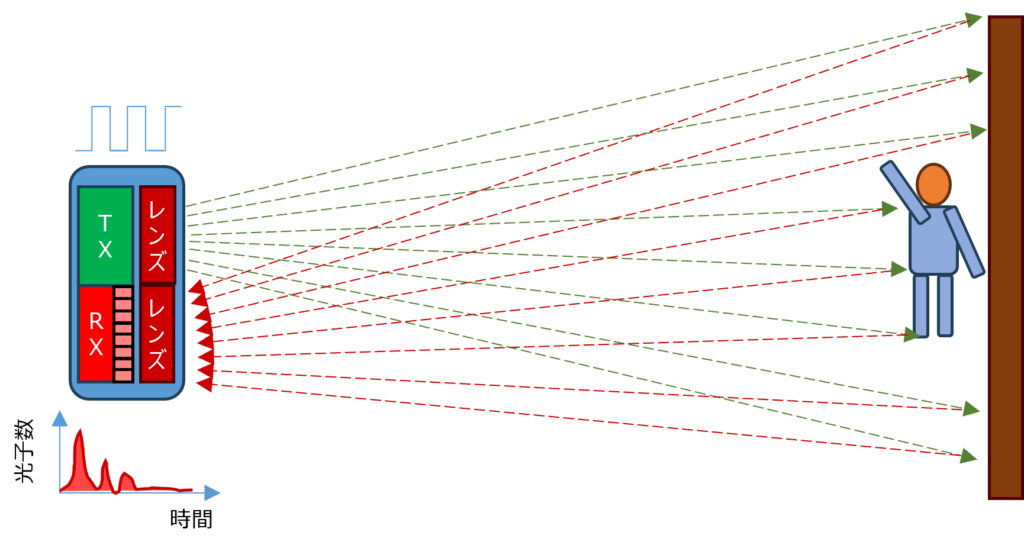
AIと低コストのTOFセンサーの組み合わせが、人の検出や転倒検知などに利用できる可能性をPoC(Proof of Concept)の結果が証明しました。さて、次のステップは何でしょうか?それは、システムをPoCから実用製品へと発展させることです。
前回の記事はこちらです。
POC から製品化へ
このフェーズでは、主に「簡略化によるシステムコスト削減」と「インフラ」の2つの領域に焦点を当てていきます。
簡略化によるシステムコスト削減
①デバイス上での処理

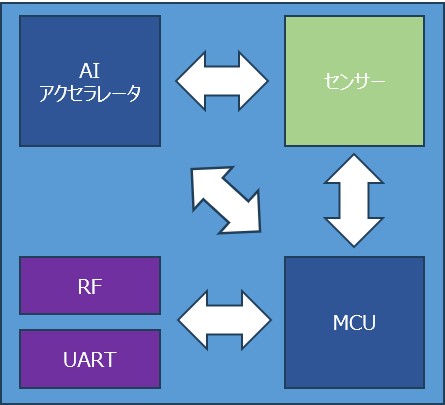
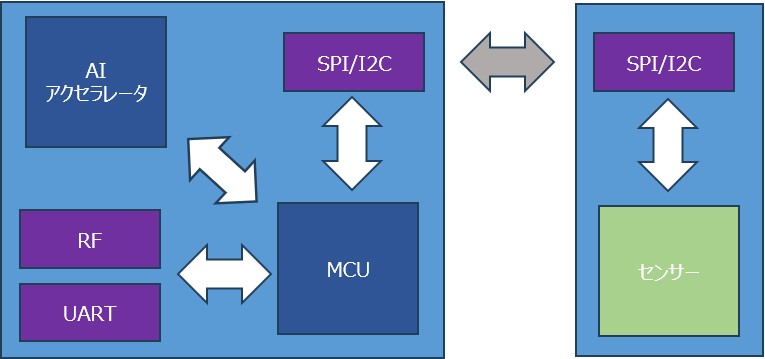
注目したいのは、デバイス上での処理です。実は、AIモデルは32ビットのM4 Cortex MCU上で直接処理することが可能。これにより、コストを抑えつつも性能を高めることができます。 具体的には、STM32ビットM4 Cortex上のAIモデルは約41KBのFlashと約12KBのRAMを使用しています。AIモデルは量子化されており、float32モデルからint8ベースに変換されています。このおかげでAIモデルのサイズが削減されるため、32ビットMCU上での高速処理が実現できるのです。 またAIモデルの推論時間は約4msですが、センサーデータの読み取り、前処理、後処理をすべて含めると、1フレームのToFデータ処理にかかる時間は10~15ms。ToFセンサーのフレームレートが8Hzであることから、最も長くて1秒あたり120msの処理時間になります。処理時間の約88%の時間をMCUはアイドル状態になるため、その間、理論上は低消費電力モードやスリープモードに移行可能です。
②インフラ
一方で、システムの中でもっとも課題となるのが「インフラ」です。これには次のような要素が含まれます:
- 接続性(Connectivity)
- システム統合に不可欠なBluetooth、UART、WiFiなど。
- 筐体
- センサー保護(防水、防塵 など)
- 電源(Power)
- バッテリー駆動または有線電源の選択肢。
システムの改善に向けて
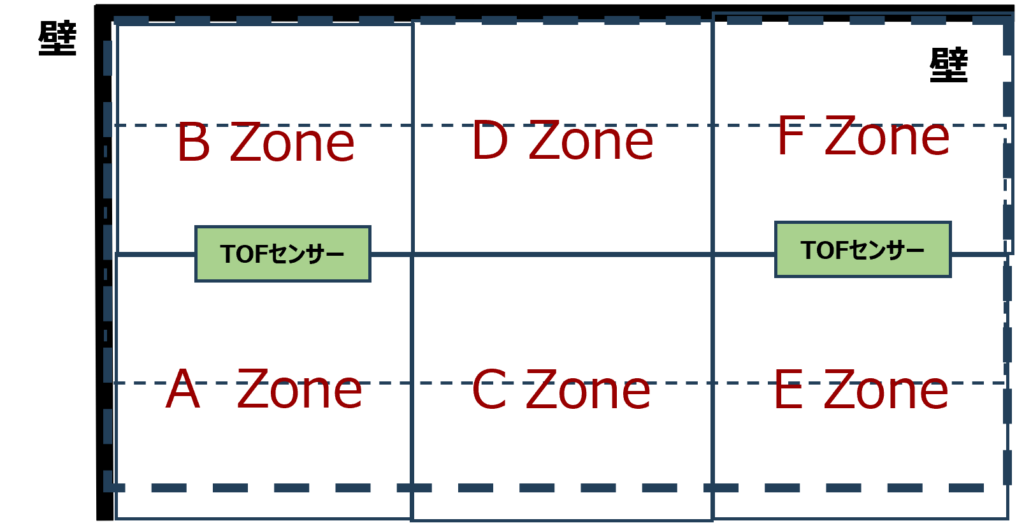
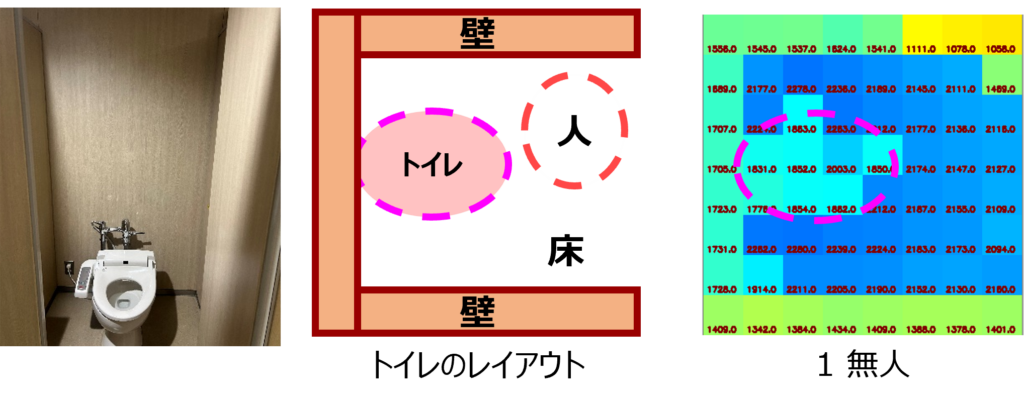
現状のシステムは低コストのTOFセンサーを使用していますが、コストを最小限に抑えながら性能の向上や機能の拡張を目指す必要があります。特に、家具や設備が固定されている環境では、無人時に取得したキャリブレーションデータをAIモデルが活用できます。しかし、患者の移動式ベッドが動いた場合や、大型の物体がセンサー範囲に入って来る場合など、シナリオによっては想定外の事態が生じることがあります。
このような状況への対策として、以下のような解決策が考えられます。
- 低コストの高解像度ToFセンサーを使用する
- 複数のセンサーを使用し、データ融合を行う
低コストの高解像度ToFセンサーを使用する
2025年末には、解像度52×42の新しいセンサーが登場予定。このセンサーはスマートフォン向けに開発されるため、低価格での提供が期待できます。これにより、キャリブレーションデータなしでも体の部位を検出できる可能性が広がります。
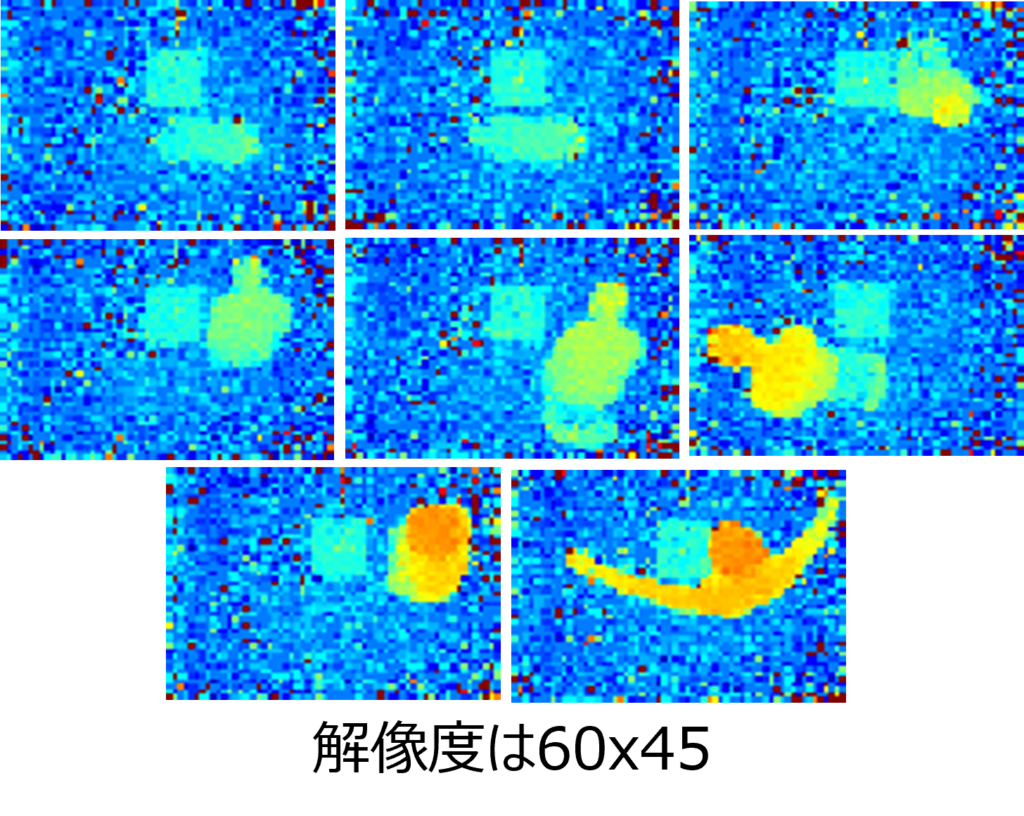
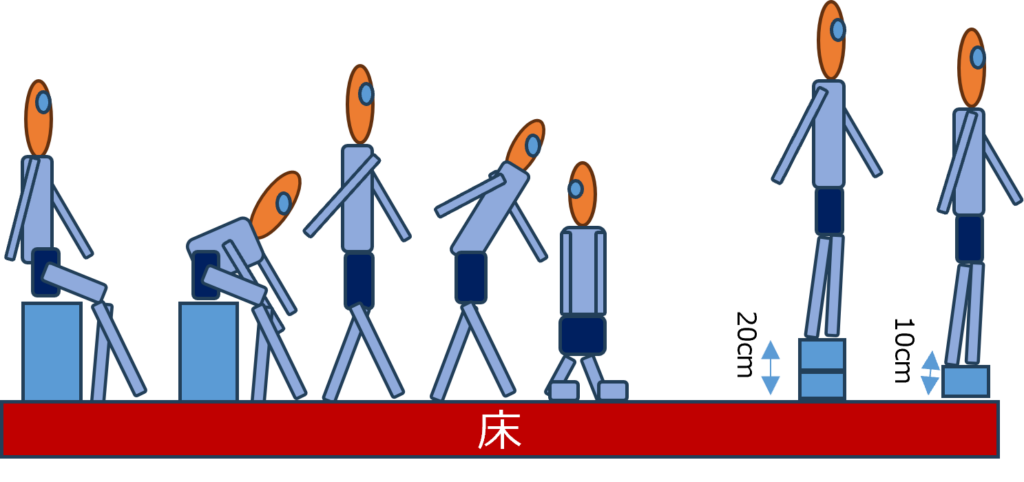
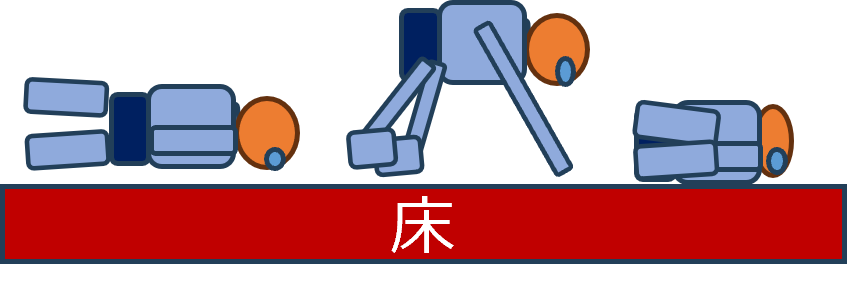
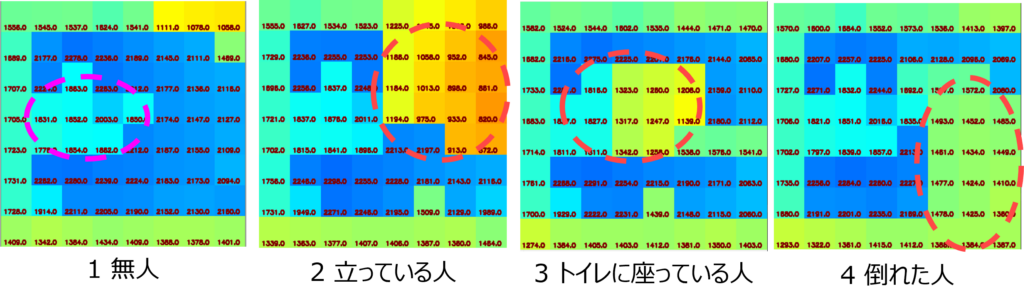
上の画像は、60×45の高解像度ToFセンサーからダウンサンプリングした画像の一部を示しています。人物は 立位、膝立ち、座位、または倒れた状態 になっています。プライバシーの観点から見ると、顔は判別できず、また体の画像も十分な詳細がないため、プライバシー上の問題は生じにくいと考えられます。
複数のセンサーを用いたデータ融合を行う
サーマルセンサーには検出範囲の制限があり、またToFセンサーよりもコストが高く(3~5倍)別の課題があります。しかし、低解像度のサーマルイメージセンサーと低解像度のTOFセンサーを組み合わせることで、物体の温度情報を活用し、人間と非人間の物体を区別できるようになるかもしれません。これにより、システム全体の精度の向上が期待されます。
さらなるユースケースの探求
顧客が関心を持つユースケースはさまざまです。例えば、
- 患者ベッドモニタリング
- 温泉

これらのユースケースは、転倒検知や危険な姿勢の早期発見に焦点を当てています。たとえば、ベッドからの転落や温泉での居眠りなど、安全面を考慮したシステムが求められています。 高解像度センサーやハイブリッドソリューションを活用することで、プライバシーを保護しつつ、より高度な検出システムを構築できる可能性があります。これにより、AIとIoT技術が目指す未来の実現に近づくことができるのです。