
エッジ デバイスやさらに小さなIoT デバイスで使用できる小さな AI モデルを作成する、駐車場AI R&D チャレンジの2回目です。オープンソースを活用しながら低コストでの開発をしています。
今回はそうしたエッヂAI開発でありがちな、乗り越えなければならない課題をお話します。
AI モデルのサイズとパフォーマンス
オープンソースのオブジェクト検出 AI モデルはたくさんあります。 なかでも有名なのはYolo(You only look once) です。 こうしたオープンソースの検出モデルは、多くの研究データ セットで高いスコアを達成する素晴らしいものです。

ただ、小さなオブジェクトやオブジェクトが密集しているケースなどでは、検出パフォーマンスが低下する傾向があります。加えて、CPUを集中的に使用し、GPU をサポートしないようなエッジ デバイスやIoTデバイスでは、画像のフレーム レートは遅くなるので、さらにパフォーマンスに影響を与えます。
Yoloモデルのサイズは、数百メガバイトから 5 ~ 10 メガバイトまでさまざまあるのですが、 最適化されたモデルが小さいほど、パフォーマンスが低下しますので、今回のエッジAI開発のような、メモリの小さな環境ではかなり厳しい想定はありました。
とはいえ、今回の目的はそうした環境下でも「画像内の 1 つ以上のオブジェクトタイプを検出できる AI モデルを作成すること」です。
もしCPU のみのエッジ デバイスで 5 以上のフレーム レートで機能するAIモデルが実現できれば、さらに難度の高いAI/IoT デバイスでもAIモデルが実行できる可能性がありますのでやる価値はあります。
私は今回のAI モデルのサイズの目標を、エッジ デバイスの場合は 2 Mb 以下、さらに小さなAI/IoT デバイスの場合は 400kB 以下と置いて開発をすすめました。
データセットの注釈(アノテーション)

AIモデルの実行環境と同じくらい重要なのが、データセットの注釈(アノテーション)です。
有料のアノテーション済の学習データ(教師データ)は便利ですがご存じの通り高価ですので、今回は無料で扱えるKaggleのデータベースを使うことにしました。
Kaggleのデータセットのデータは4000ほどありましたが、アノテーションが付いておりません。
付けなければなりませんが、人によるアノテーションはお察しの通り途方もない作業で、開発者が自ら行うのは無理があります。そこで、前述の著名な物体検出 AI モデルの「 Yolo」 で車を認識させアノテーションを自動設定しようと試みました。
ところが、これがうまくいかないのです。
私の感覚ですと、どうもこの「Yolo」はおおまかに1画像に移っている車の数の20%~40%程度しか車を認識しませんでした。
なぜか。
どうやら映像内で並んでいる車のサイズが小さすぎて、前述した「小さなオブジェクトやオブジェクトが密集しているケース」に相当してしまいYoloが認識できないのが原因のようでした。
結論として今回Yoloが使えないことが分かったので、もう自作しかないと思った私は、映像内の車の位置を記録するアプリケーションをカスタム製作することにしました。
詳細はまた機会があればご紹介しますが、このアプリがうまく各車の位置をアノテーション記録してくれたので、AIモデル学習、その後のAIモデルのイメージ マスク出力までできるようになりました。
データセットのバランス
データ セットの課題はもう1つあります。それはデータセットのバランスです。
データセットのバランスとは、極端に似たデータばっかりセット内に存在するとか、逆にあまり存在しないデータがあるといった不均衡、不均一なデータであることで、そのままAIが学習するとAIモデルの性能評価に偏りが生じる可能性があります。
今回の駐車場のデータセットでもいろいろとありましたが、まとめるとこんな感じです。
- 気象条件による明るさの変動
- 影による画像の明るさの変化
- 明るい日差しの中で白い車
- 暗い場所の黒い車
- 植物の問題
- データセット大きな偏り
- 一部の車種の形状
以下簡単にご説明いたします。
1.気象条件による明るさの変動
これは、霧がかかった冬の日から、明るい夏の日までさまざまな状態があります。こうした季節や気象の変化で駐車場の映像の明るさも刻々と変化します。この変動はAIモデル学習に影響を与えます。
2.影による画像の明るさの変化
また、1日の時間帯の条件も難しい時があります。朝から夕方までの太陽の位置で周囲の明るさ自体が変わります。また特に朝夕などで太陽の位置が傾いているときの映像データですと、出来る影が車の周囲に発生をして、これが邪魔をしてAIモデルが車を見分けにくくなることがあります。

3.明るい日差しの中で白い車
たとえば、明るい朝の日差しの中に白い車があるような状況です。こうなると周囲の明るさに車が埋没するので、カメラ センサーが飽和状態になり、車の特徴が見分けにくくなります。

4.暗い場所の黒い車
これは前述の逆パターンで、薄暗くなった夕方になって駐車場へやってきた黒い車は、車とその周囲の明るさが似ていてAIが認識しにくい、という問題を引き起こします。

5.樹木の問題
これもよく問題になります。この駐車場データの右下にある車は、その前にある木々の枝が茂っており、部分的に遮られています。落葉樹ですと冬には葉がありませんが、夏には葉がもっと茂るので、認識率もさらに変わってくることになります。

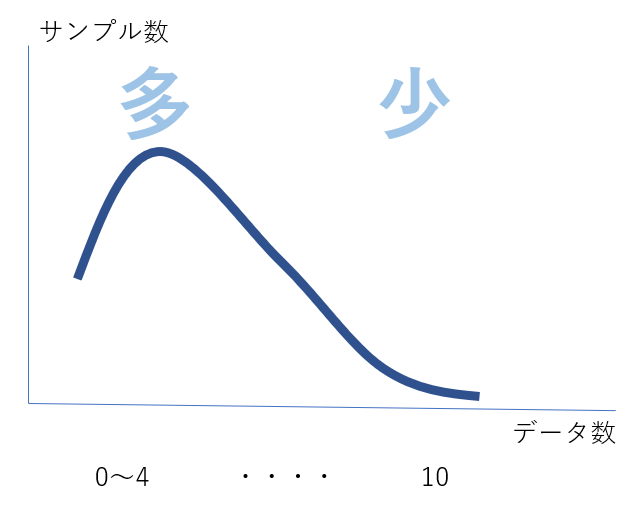
6.データセットの大きな偏り
この重要度は前述しましたが、駐車場の映像でのデータセットの偏りとは、なんだかわかりますか?
実は「駐車台数」です。
実際に学習用に入手できた駐車場画像は0~3台ほどが停車しているものが大半で、Kaggleでは4台~というものがほとんどなかったのです。ですので、このまま学習をすすめると、学習に大きな偏りが生じる、という問題を発生させます。
7.一部の車種の形状
こちらも前述いたしましたが、車の形状が大きく違う場合、認識率が落ちることがあります。たとえば、RVやセダンなどが多い国の映像を中心に学習していると、たまに停めに来る大型トラックなどを車と認識しない、ということが起きます。
以上、オープンソースを活用しながら低コストでエッジAI開発をするときの、AI モデルのサイズとパフォーマンス、そして駐車場データセットの課題についてまとめてみました。
いかがでしょうか。皆様の開発の参考になると嬉しいです。
次回は、これらの課題克服のポイントなどについてお伝えしようと思います。


